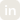Products
Bud AI Foundry
The all-in-one control panel for enterprise GenAI. A unified platform to experiment, build, scale, and consume private and cloud AI models and agents.
Multi-modal Inference
Model Management
Guardrails
Observability
Bud MCP Foundry
The universal MCPfication platform for enterprise AI transformation. Turn existing tools, workflows, and APIs into governed MCP tools while federating 1,000+ third-party MCPs through one unified control plane.
MCP Generation
Unified Federation
Governance Plane
Enterprise Ready
Bud Sentinel
AI guardrails powered by Resource Aware Attention. Faster on any CPU than competitors on a $15K GPU with industry-leading accuracy.
CPU-Optimized
Low Latency
High Accuracy
Edge Ready
Bud Cache
The enterprise-grade, accuracy-first response cache for Large Language Models. Reuse answers across genuinely equivalent requests on commodity CPUs, cutting inference cost and latency without ever serving a wrong answer.
Near-Zero Wrong Answers
Sub-millisecond, CPU-only
Self-Tuning
GDPR-Ready
Bud Model Foundry
Build, fine-tune, and ship custom models at scale. A complete foundry to train, evaluate, and deploy domain-specific models on your own infrastructure.
Fine-tuning
Evaluation
Custom Models
Deployment
GenZ
A powerful general-purpose LLM finetuned for reasoning and instruction-following. Optimized for enterprise workloads with strong performance across benchmarks.
General-purpose
Reasoning
Instruction-tuned
Benchmarked
Code Millennials
State-of-the-art code generation model. Finetuned for software development tasks with strong performance on coding benchmarks.
Code Generation
Developer Tools
High Accuracy
Multi-language
Bud Models
Explore the full collection of Bud's domain and use-case specific finetuned models. Optimized for performance across various industries and applications.
Domain-specific
Fine-tuned
Optimized
Production-ready
Bud SENTRY
Zero-trust model ingestion framework integrated within Bud Runtime. Protects against supply chain attacks with sandboxed evaluation, deep scanning, and continuous runtime monitoring.
Zero-Trust Ingestion
Sandboxed Evaluation
Malware Scanning
Runtime Monitoring
Bud FCSP
Full-stack AI compute and service platform. End-to-end infrastructure for deploying, scaling, and managing AI workloads in the cloud.
Cloud Infrastructure
Scalable Compute
AI Workloads
Managed Services
Bud Latent
Advanced latent space exploration and representation learning. Unlock deep insights from your data with state-of-the-art embedding and feature extraction.
Latent Space
Embeddings
Feature Learning
Data Insights
Resources
Solutions
Bud For Cloud Service Providers
Transform from bare metal provider to AI-first cloud platform. Enable Model-as-a-Service, Token-as-a-Service, and AI PaaS offerings with enterprise-grade infrastructure.
Model-as-a-Service
Token-as-a-Service
AI PaaS
Sovereign AI
Bud For Original Equipment Manufacturers
Ship AI-native devices that work out of the box. Pre-integrated AI stack with zero-config deployment, OTA updates, and enterprise security built in.
AI-in-a-Box
Zero-Config Deploy
OTA Updates
Edge Security
Bud + Dell AI in a Box
A turnkey private AI appliance pairing Bud's inference stack with validated Dell infrastructure. Deploy enterprise GenAI on-premises with zero setup — pre-integrated, tested, and ready to run.
Turnkey Appliance
On-Prem GenAI
Dell Validated
Zero Setup
Bud + AMD AI Foundry
An enterprise AI Foundry optimized for AMD Instinct accelerators. Run, scale, and govern private and cloud AI models on AMD hardware with full performance and no vendor lock-in.
AMD Instinct
Optimized Inference
Open Ecosystem
Cost-Efficient
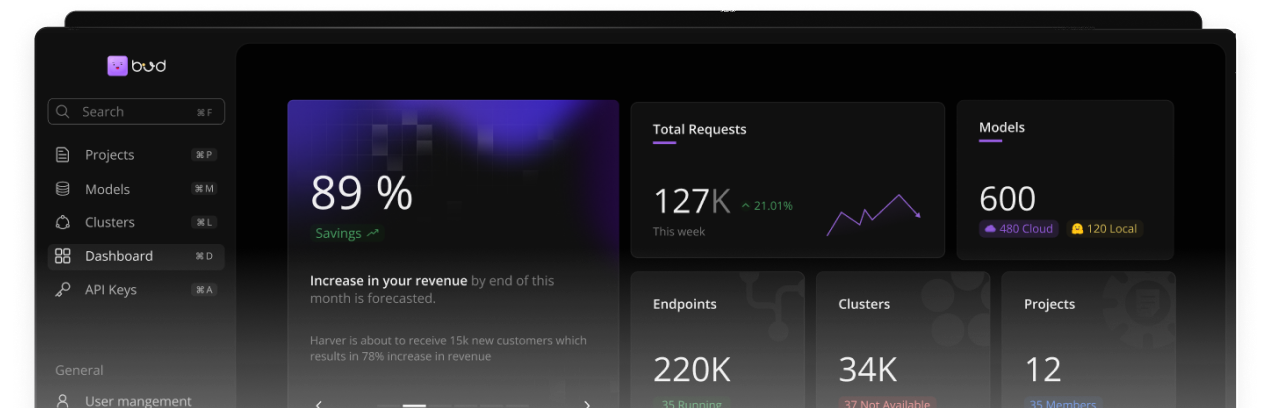












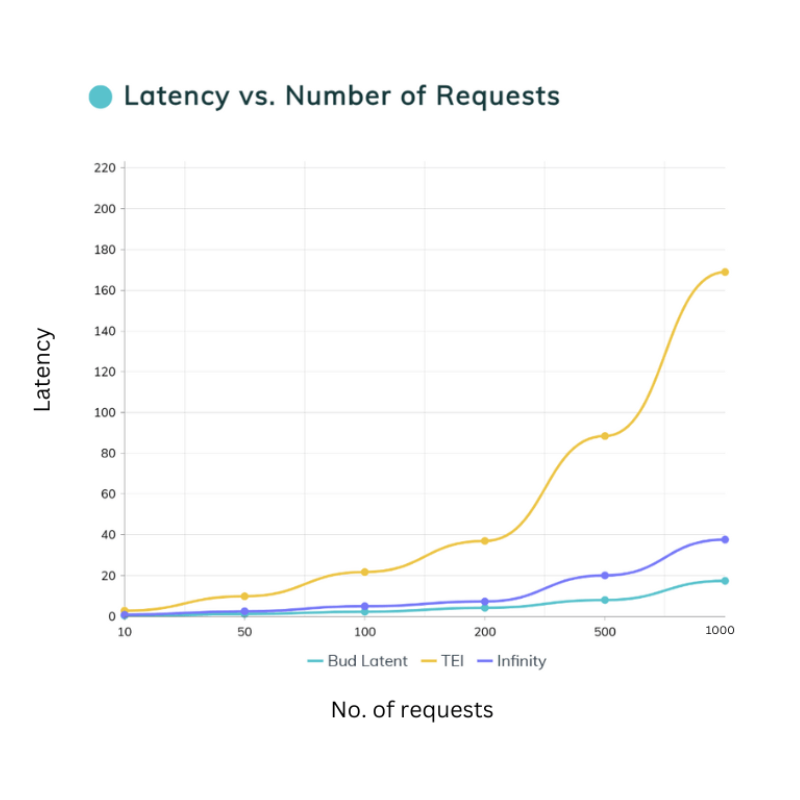
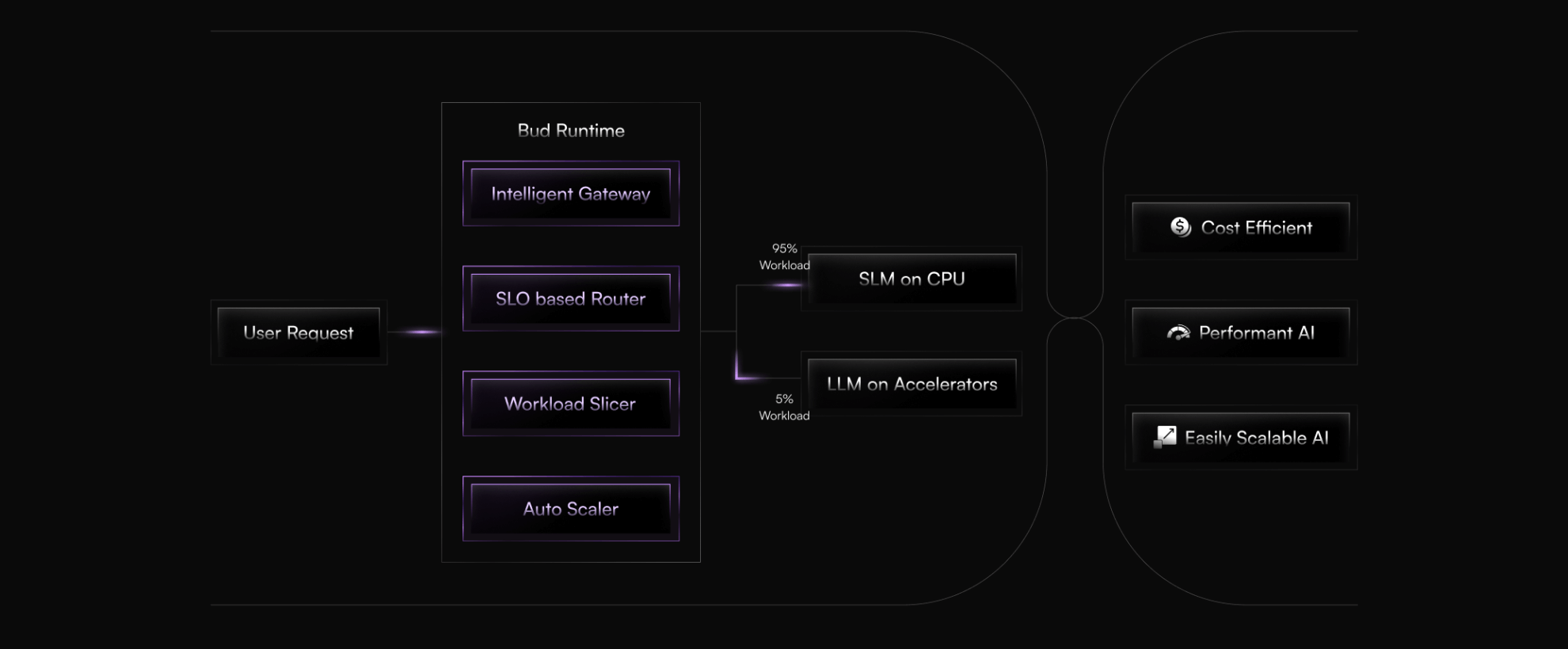




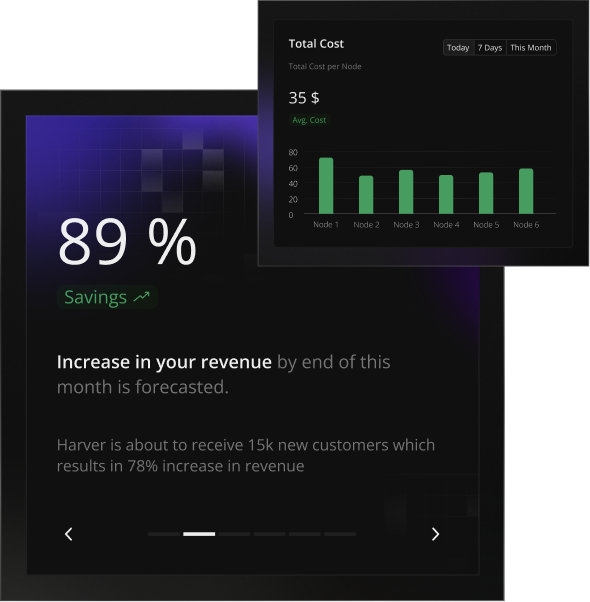





















.png)