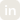Every enterprise deploying generative AI eventually arrives at the same uncomfortable realisation: the world’s best pre-built guardrails are still written by someone else, for someone else’s rules.
Out-of-the-box safety layers do an admirable job on the universal hazards — profanity, personally identifiable information, prompt injection patterns, clearly toxic content, explicit refusals of hate speech. These are table stakes, and the incumbent providers handle them well. But “toxic in general” and “unsafe for us” are two very different problems. The moment an AI system starts handling real enterprise work — employee conversations, customer escalations, regulated transactions, clinical triage, financial advice, legal intake — the interesting risks stop being universal. They become specific.
They become yours.
And that is precisely where generic guardrails have nothing useful to say.
Every organisation has its own definition of what’s acceptable, its own escalation paths, its own regulatory perimeter, its own list of words legal has quietly banned from customer-facing copy, its own edge cases that only reveal themselves after the third production incident. No pre-trained safety classifier — no matter how sophisticated — can know any of that. It wasn’t in their training data. It isn’t in their policy library. It never will be.
For serious enterprise AI, the question isn’t whether you need custom guardrails. It’s how you can possibly afford to build them.
Why organisation-specific guardrails are non-negotiable
To see why custom policies matter, it helps to move away from abstractions and look at what actually happens inside a deployed AI system. For example,
The HR agent: Imagine you’ve rolled out an internal HR assistant. An employee opens a chat and, haltingly, starts describing a harassment incident at work. This is profoundly sensitive territory — the kind of conversation where getting the response wrong isn’t just a product quality issue but a human, legal, and reputational one. The AI shouldn’t attempt to handle this on its own. It should recognise what is happening and immediately route the conversation to a human HR partner, with the appropriate confidentiality and duty-of-care framing. A generic toxicity classifier will not catch this. The employee’s language isn’t toxic. It’s vulnerable. That is a domain-specific signal that only your HR policy knows how to read.
The financial services copilot: An internal assistant at a wealth management firm is asked by a customer-facing advisor to “give me a recommendation for this client’s portfolio.” In most regulatory regimes, an unvetted AI recommendation crossing into an advised client interaction is a suitability issue, not a content issue. The words are perfectly polite. The risk is structural. Only a custom policy — one that encodes your firm’s definition of what constitutes advice, for which client types, and under which supervisory arrangements — can catch it.
The healthcare triage assistant: A patient describes symptoms that, in your clinical protocol, constitute a red flag requiring immediate human clinician review. The AI must not reassure, must not triage to a later appointment, must not continue the conversation. It must hand off. The words that trigger this behaviour are clinical, context-dependent, and specific to how your organisation has chosen to interpret its duty of care. An off-the-shelf medical safety filter won’t know your protocol.
The legal intake bot: A user on a law firm’s website asks a nuanced procedural question. Your professional-responsibility framework draws a hard line between general information and legal advice, and the line sits in a different place than the general-purpose “don’t give legal advice” rules a public model has been trained on. Your probe has to enforce *your* line, not someone else’s.
The customer support agent: Your support assistant is authorised to offer a 10% goodwill credit, but not a 30% one. It can mention the existence of your premium tier, but not compare your pricing to a named competitor. It can acknowledge a known outage, but only once the incident has been publicly disclosed. These are not safety issues in the conventional sense. They are operational policy. And yet, the moment any of them are violated, the business takes real damage.
The procurement and manufacturing assistant: An engineer asks for recommended operating parameters for a piece of equipment. Your internal safety protocol permits a narrower range than the manufacturer’s public spec sheet. A generic assistant will happily regurgitate the manufacturer’s numbers. A correct one will enforce your plant’s conservative envelope.
Every one of these cases has the same shape: the words on the screen are not the risk. The context is. The policy is. The organisation is. And no pre-trained guardrail — no matter how capable — has ever heard of your organisation.
The hidden tax on enterprise guardrails today
Teams that have tried to build custom guardrail coverage know the problem isn’t that the need is unclear. It’s that the available paths to meet that need are each, in their own way, punishing. There are three taxes that compound on top of each other.
1. The cost tax
Guardrails run on every input, every output, and — in agentic systems — every intermediate action. That means for every token a user sends and every token the model returns, a separate model somewhere is also doing work. The guardrail layer is, effectively, a shadow inference pipeline running in parallel to the primary one.
In practice, this has a habit of quietly becoming one of the largest line items in an AI program’s budget. Teams discover, months after shipping, that their guardrail costs are comparable to their primary model costs — sometimes higher, especially when multiple probes are stacked for defence in depth. The economics are particularly painful for high-volume, low-margin use cases like customer support, where every cent of per-interaction cost translates directly into a business case that does or doesn’t work.
And the pressure only increases as adoption scales. The more valuable an AI deployment becomes, the more traffic it attracts, and the more aggressively guardrail costs compound. Teams have been forced into ugly trade-offs: thinner guardrail coverage to preserve unit economics, or better safety at margins that can no longer be justified. That is not a choice any responsible organisation should have to make.
2. The model training tax
The traditional way to encode organisation-specific rules into a guardrail is to train your own classifier — a dedicated model that reads the input or output and decides whether it violates your policy. This is how safety has historically been done in ML. It also happens to be completely unrealistic for the vast majority of organisations deploying AI today.
Training a custom guardrail model requires, at minimum:
- Labelled training data, usually in the thousands of examples, often tens of thousands for anything nuanced. Producing this data is slow, expensive, and requires subject matter experts who are already in short supply.
- An evaluation harness sophisticated enough to catch regressions and distinguish genuine policy shifts from statistical noise.
- MLOps infrastructure for training, versioning, deploying, monitoring, and rolling back models.
- ML engineering and applied research talent capable of building all of the above — the scarcest and most expensive talent in the technology market.
- Iteration cycles, because nobody gets a guardrail model right on the first attempt. Every edge case you discover in production is another retraining round.
Most enterprises — even highly sophisticated ones — do not have these capabilities sitting in-house, and cannot realistically acquire them at the speed their AI roadmaps demand. The practical effect is that custom guardrail models are built by the few, while the many deploy AI with coverage they know to be incomplete, and hope. That is not a sustainable risk posture.
3. The time tax
Even for organisations that can afford the first two taxes, there is a third: time. By the time a custom classifier is labelled, trained, evaluated, and signed off by the safety and compliance teams, the underlying policy has often moved. A new regulation has dropped. A legal decision has reshaped what “appropriate advice” means in your jurisdiction. Your HR team has expanded their definition of escalation-worthy conduct. Your marketing team has rebranded a product.
Safety that ships six months after it was needed is not safety. It is a liability dressed in the language of diligence. In a domain where policy evolves constantly, the build cycle for traditional guardrail models is structurally mismatched to the cadence of the business.
The shape of a better answer
Step back from the specifics, and the nature of the problem comes into focus. Enterprises don’t actually need the ability to train custom models. They need the ability to express custom *policies*. The “model” is incidental — a means to an end. What the business actually has, and needs to encode, is judgement: definitions, interpretation rules, examples of what’s safe and what isn’t, an explicit position on ambiguity.
That is not a machine learning artefact. That is a policy document. If a system could read a well-written policy document and enforce it at inference time — with the same nuance and edge-case reasoning that a human reviewer would apply — the entire problem structure changes.
The cost tax shrinks, because you’re no longer running a second model train for every new policy. The training tax disappears, because there’s no training. The time tax collapses, because the distance from “policy decision” to “enforced behaviour” is measured in minutes, not quarters.
How Bud AI Foundry changes the equation
Bud AI Foundry treats guardrails as a first-class capability of the platform rather than a side accessory bolted onto inference. Two design decisions, in particular, matter for the custom-policy problem.
The first is Bud Sentinel, the enforcement layer that runs guardrail policies at inference time. Sentinel is engineered specifically for the economics of production AI. It addresses the cost tax head-on: guardrail evaluation is no longer a parallel inference pipeline with its own budget profile, but a tightly integrated step whose cost structure is designed for the realities of high-volume enterprise workloads. For teams that have been rationing guardrail coverage in the name of unit economics, that alone changes what’s possible. Defence in depth stops being a luxury.
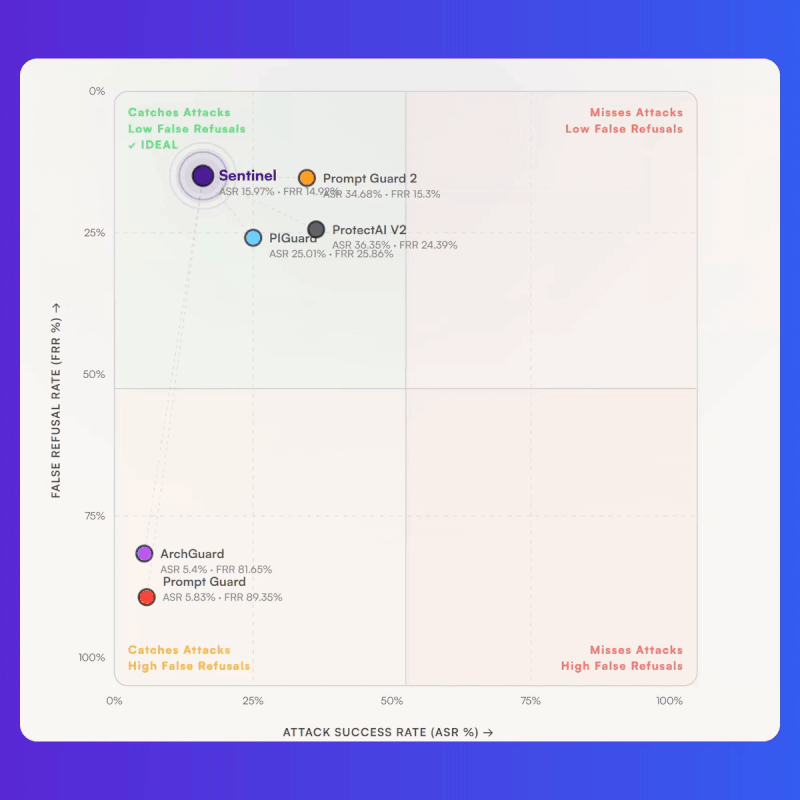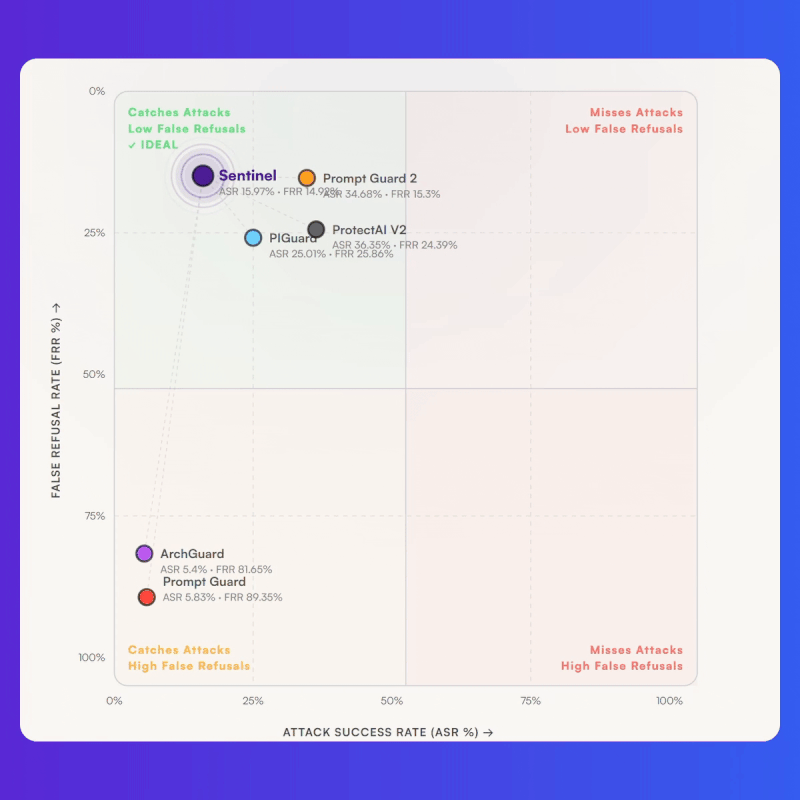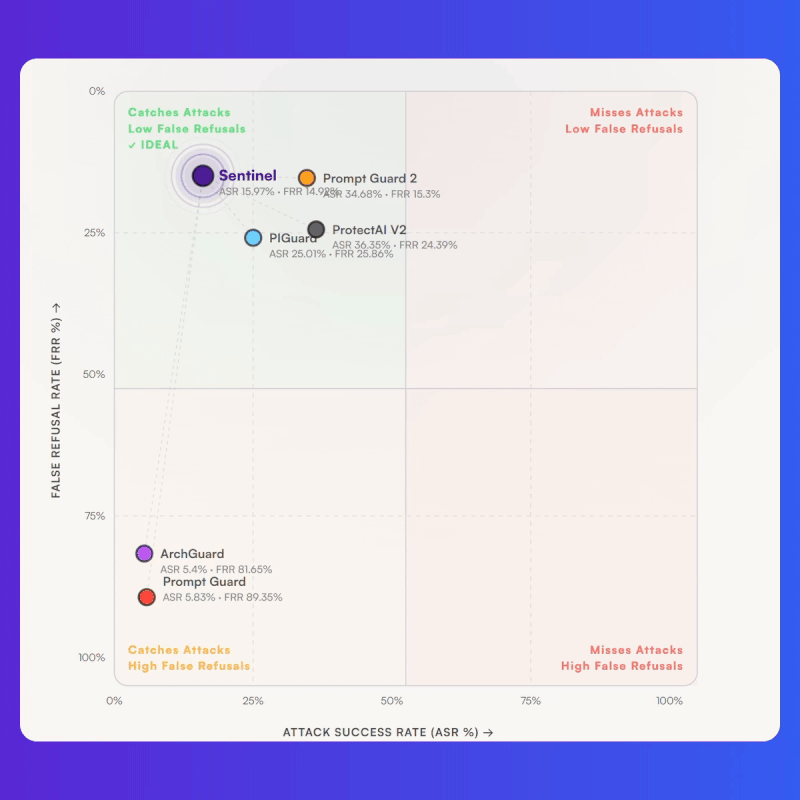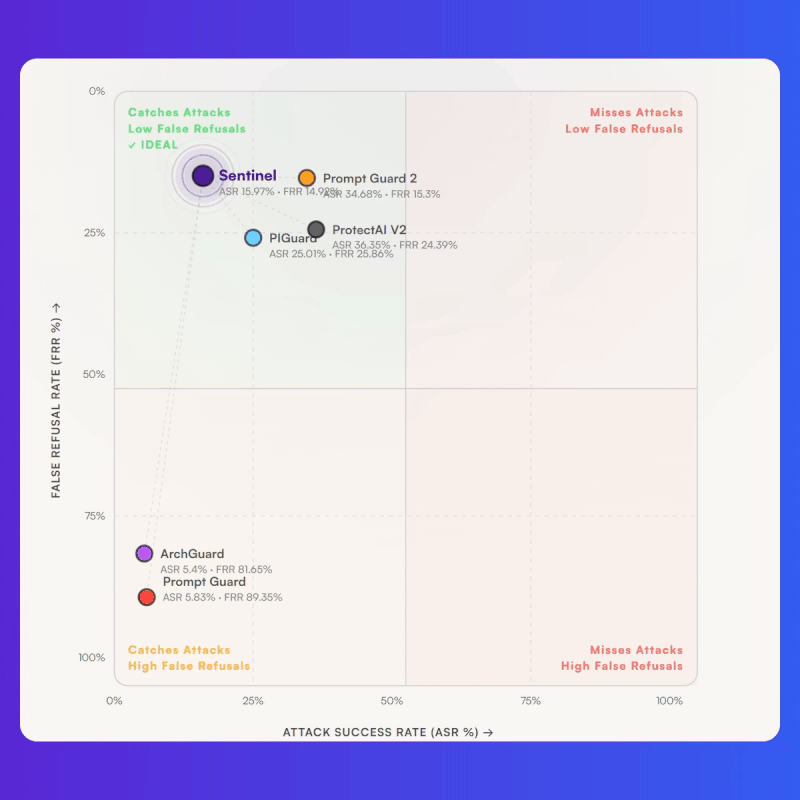
Bud Sentinel removes the cost tax entirely. Built on Resource Aware Attention, it runs all 23 guardrail models on commodity CPUs with state-of-the-art accuracy, clocking 8.39ms on a laptop CPU against roughly 18 to 19ms for competing models running on a $15,000 A100. The cost math shifts just as sharply: CPU cloud instances run at around $0.50 per hour versus $2 to $3 per hour for A100 instances, producing a 15 to 18x cost-performance advantage and bringing the unit economics down to about $0.10 per million classifications. There is no GPU procurement, no cluster management, and no infrastructure refresh required, and the same binary deploys cleanly into public cloud, on-prem, air-gapped, and edge environments. The net effect is that guardrails stop being a cost centre organisations ration across their most sensitive workflows and become ambient infrastructure that can run on every agent action, every tool call, and every model output without a GPU ever entering the loop.
The second is custom probe creation without model training. This is the change that resolves the training tax and the time tax together. Instead of handing your policy to an ML team and waiting, you encode the policy directly — in natural language, with structured fields designed to capture exactly the kind of judgement a human reviewer would bring to a borderline case. The probe reasons over your policy at inference time. No labelled dataset. No training run. No MLOps pipeline. No waiting.
The effect is to move guardrail creation from an engineering project to a policy-authoring exercise. The people best positioned to define what’s acceptable — your compliance officer, your HR lead, your head of clinical operations, your customer experience director — can actually express that definition themselves, rather than translating it through a game of telephone that ends at a data labelling spreadsheet.
This is a meaningful shift in who owns AI safety inside the enterprise. It stops being a bottleneck inside the ML team. It becomes a direct expression of the subject matter experts who understand the domain.
Walking through a custom probe, end to end
To make this concrete, consider the HR harassment scenario from the beginning of this article. Here is what creating the corresponding custom probe in Bud AI Foundry actually looks like.
From the Bud AI Foundry dashboard, you navigate into the Guardrails module and click Add Guardrail. You’ll see an option to Create Custom Probe; selecting it takes you to the probe definition screen.
This is where the intelligence of the probe gets assembled. The flow is deliberately designed around how a human policy author actually thinks — definitions first, then interpretation, then examples, then ambiguity handling. The video below walks you through the process of creating custom guardrails in Bud AI Foundry.
Task description
The first field is a plain-language statement of what this probe exists to catch. For the HR scenario, it might be a description for a custom policy to detect harassment incidents surfaced by employees during an AI-mediated interaction, and ensure such cases are routed for human handling rather than answered by the agent.
The point of this field is not decoration. It is the north star that every other field in the probe should align with. A sharp task description is the difference between a probe that protects your users and a probe that drifts over time.
Definitions
Next is the vocabulary of your domain. This is where you teach the probe the language your organisation actually uses — domain-specific abbreviations, internal terminology, your policy-specific interpretations of loaded words.
This matters more than it looks. Without explicit definitions, the probe falls back on whatever general-purpose meaning the underlying model has learned from the public internet. “Harassment,” in a legal policy sense, has a different shape than “harassment” as used in everyday speech. “Hostile work environment” has a precise legal threshold that differs from the colloquial usage. If you want the probe to apply your organisation’s interpretation of the rules, those interpretations need to be stated. Otherwise the probe is, in effect, enforcing someone else’s policy by accident.
Interpretation rules
These are the conditional logic statements that tell the probe when to fire and when to hold back. They are how you encode the “if this, then that” judgements that sit underneath your policy.
For an HR probe, an interpretation rule might capture the distinction between an employee raising a live incident versus an employee asking a procedural question about company policy. Both conversations contain the word “harassment.” Only one of them represents an active escalation that needs a human.
Interpretation rules are how you make that distinction explicit, rather than leaving it to the probe’s instincts.
Evaluation approach: Depiction, Request, Guidance
This is the probe’s reasoning lens. Three sub-fields work together:
- Depiction tells the probe what kind of content it’s looking at — employee message, LLM output, agent-initiated action — so it approaches the content with the right framing.
- Request tells the probe what specific question to answer about that content. Not “is this bad?” but a precise, narrow question anchored in your policy: “Is this employee describing, or in the process of reporting, conduct that would meet the organisation’s threshold for a harassment incident?”
- Guidance provides the reasoning framework the probe should apply at inference time — the chain of considerations a careful human reviewer would walk through when adjudicating a borderline case.
The combination gives the probe a consistent lens. Every case gets examined with the same intent, using the same question, applying the same reasoning approach. That consistency is what separates a defensible guardrail from a coin flip.
Safe content
It is tempting, when building a safety probe, to focus entirely on violations. This is almost always a mistake.
A probe that over-blocks is its own category of failure. An HR assistant that refuses to answer a benign question about company anti-harassment policy because it spotted the word “harassment” has stopped being useful. Worse, it has trained employees to stop trusting the tool. Over time, they route around it. That is a safety failure dressed up as safety success.
Explicitly defining the safe content types — the cases that *contain* the policy’s key terms but are not themselves violations — prevents this drift. For the HR probe, a casual policy question is safe content. A manager asking about training materials is safe content. An employee in a company-sponsored discussion group is safe content. Defining these cases as clearly as the violations is what gives the probe real discrimination.
Training examples
The probe sharpens on labelled examples. A working minimum is around five, but seven or more — especially covering the edge cases your specific deployment will encounter — is materially better.
Crucially, these examples are not a training dataset in the machine-learning sense. No gradient descent happens. Instead, the examples serve as illustrations the probe reasons *with* at inference time — concrete anchors that demonstrate how to think about a case, particularly the boundary cases where reasonable people might disagree. Labelling and explaining those boundary cases is what teaches the probe to reason through ambiguity instead of pattern-matching on surface keywords.
This is the single largest practical difference between training a classifier and authoring a probe. One requires thousands of labelled rows and a data pipeline. The other requires a handful of carefully chosen examples that capture the real-world nuance.
Violations, organised by severity
Violations are grouped by severity so that downstream systems can respond proportionally. A low-severity policy drift should not be handled the same way as a live harassment report. Treating every violation identically — either by over-escalating minor infractions or under-responding to serious ones — is another failure mode custom probes need to avoid.
Severity stratification lets the rest of your stack act intelligently: a soft warning for the minor case, immediate human handoff for the serious one, a policy-specific escalation path for everything in between.
Ambiguity handling
Finally, and importantly, you tell the probe exactly what to do when a case doesn’t fall cleanly into safe or violating territory.
Real production traffic lives in the grey zone. A probe with no explicit ambiguity rule will either freeze on uncertain cases or default to whatever implicit bias the underlying model happens to have. Neither is acceptable for enterprise use.
Explicit ambiguity handling lets you state your organisation’s position: default conservative, route to a human, apply a specific combination rule, allow with a flag. Whatever the right answer is for your policy, the probe now knows to act in that direction — every time, consistently — when it encounters the unknown.
What this unlocks, in practice
It is easy to read the workflow above and miss the strategic consequence of it. Let’s name it plainly.
Safety becomes a product of the business, not the ML team. The people who understand your policies best are now the people encoding them. That shortens feedback loops, reduces translation errors, and makes AI safety an ongoing collaboration rather than a quarterly hand-off.
Defence in depth becomes economically viable. When each new probe doesn’t require training, labelling, or infrastructure, the marginal cost of adding another layer of coverage falls dramatically. Teams can afford to run multiple probes per interaction — one for harassment detection, one for competitive positioning, one for regulatory scope, one for brand voice — without breaking the unit economics of the product.
Policy can move as fast as the business. When a new regulation drops, or a legal review changes a definition, or an incident review produces a new interpretation rule, you update the probe the same week — not the next fiscal cycle. The guardrail stops being a drag on organisational responsiveness and starts being an expression of it.
The long tail becomes addressable. Most enterprise AI risk lives in the long tail of domain-specific edge cases that no off-the-shelf classifier will ever cover. Traditional custom-classifier economics meant only the top one or two risks were worth building for; everything else was accepted risk. When the authoring cost drops to the cost of writing a good policy document, the long tail becomes something you can actually close.
Ownership becomes clear. A probe with an explicit task description, definitions, interpretation rules, and named ownership is auditable in a way that a black-box classifier never was. Compliance teams can read the probe. Regulators can review it. Internal audit can trace a production behaviour back to the specific rule that produced it. That is a posture that holds up under scrutiny.
The broader shift: from safety as a model problem to safety as a policy problem
There is a quiet but important rethinking embedded in all of this.
For the better part of a decade, “AI safety” has been treated primarily as a modelling problem. Train better classifiers. Collect more labelled data. Build more sophisticated red-team evaluations. The answer to a new risk was always the same: train another model.
That framing made sense when the AI systems in question were narrow, when the risks were well-understood, and when the organisations building them were AI labs with deep ML benches. It makes much less sense in the enterprise context, where the systems are horizontal, the risks are domain-specific, and the organisations deploying AI are banks and hospitals and manufacturers whose core competency is not model training.
In this world, the binding constraint isn’t modelling capability. It’s the ability to express nuanced, domain-specific policy at the speed and cost that the business actually operates on. Custom guardrail authoring — as implemented in Bud AI Foundry — treats that constraint directly. Safety becomes a policy artefact. The policy becomes executable. The executable policy runs cheaply enough to cover the whole surface area of the deployment.
That is a quietly significant shift. It redistributes who does AI safety work inside an enterprise, what that work looks like, how fast it can move, and how much of it the organisation can afford to do. None of those changes, on their own, are revolutionary. Together, they redraw the economics of responsible AI deployment.
Closing: AI safety that fits
Every enterprise deploying AI eventually has to answer the same question: does your safety layer actually encode your organisation’s judgement, or does it encode someone else’s, with your logo on it?
Off-the-shelf guardrails will always have a role. Universal hazards demand universal coverage, and the incumbents do that well. But the risks that actually threaten an enterprise — the HR escalation that wasn’t recognised, the financial recommendation that crossed a regulatory line, the brand-damaging customer interaction that slipped through because the policy had never been encoded anywhere a machine could read it — those risks are yours. They need safety that is also yours.
Bud Sentinel addresses the cost problem that has quietly been holding enterprise guardrail coverage back. Custom probe creation without model training addresses the capability and speed problems that have kept custom policies out of reach for most organisations. Together, they let enterprises build AI safety that actually fits — defined by the people who know the policy, running at an economic profile that makes comprehensive coverage viable, and updatable at the pace the business actually moves.
That is what it looks like to move beyond off-the-shelf. Not more generic safety. Not more training budgets. Just a platform that lets your organisation’s own judgement become the guardrail.
In the next article in this series, we’ll look at how to monitor probe results in production, interpret the signals they surface, and tune your policies over time — because good guardrails, like good policy, are never a one-off decision.
FAQs
1. Why aren’t off-the-shelf AI guardrails enough for enterprises?
Pre-built guardrails handle universal hazards well, things like profanity, PII, prompt injection, and clearly toxic content. But the risks that actually threaten an enterprise are not universal. They are organisation-specific. An HR assistant needs to recognise a harassment escalation and route it to a human. A wealth management copilot needs to know where your firm draws the line between information and regulated advice. A support agent needs to know it can offer a 10% goodwill credit but not 30%. None of these are content problems a generic toxicity classifier can catch. The words on the screen are not the risk. The context, the policy, and the organisation are. Off-the-shelf safety classifiers have never heard of your organisation, so they cannot enforce its rules.
2. Can you build custom AI guardrails without training a machine learning model?
Yes. The traditional approach required thousands of labelled examples, an evaluation harness, MLOps infrastructure, scarce ML talent, and multiple iteration cycles before a custom classifier was production-ready. Bud AI Foundry replaces that pipeline with custom probe authoring. You encode your policy directly in natural language using structured fields like task description, definitions, interpretation rules, evaluation approach, safe content, training examples, severity-tiered violations, and ambiguity handling. The probe reasons over your policy at inference time. There is no labelled dataset, no training run, and no MLOps pipeline. This shifts guardrail creation from an engineering project to a policy-authoring exercise that compliance officers, HR leads, or clinical ops directors can do themselves.
3. How much do enterprise AI guardrails cost to run, and why is CPU inference cheaper than GPU?
Guardrails run on every input, every output, and every intermediate agent action, which means they effectively run a shadow inference pipeline alongside the primary model. Teams routinely discover their guardrail costs match or exceed their primary model costs. Bud Sentinel addresses this with Resource Aware Attention, which runs all 23 guardrail models on commodity CPUs. It clocks 8.39 ms on a laptop CPU compared to roughly 18 to 19 ms for competing models on a $15,000 A100. CPU cloud instances run at around $0.50 per hour versus $2 to $3 per hour for A100s, producing a 15 to 18x cost-performance advantage and bringing unit economics down to about $0.10 per million classifications. The same binary deploys into public cloud, on-prem, air-gapped, and edge environments without GPU procurement.
4. What fields go into creating a custom guardrail probe in Bud AI Foundry?
A custom probe is built from eight structured fields, ordered the way a human policy author actually thinks. Task description states what the probe exists to catch. Definitions teach the probe your organisation’s vocabulary and policy-specific interpretations of loaded terms. Interpretation rules encode the conditional logic that distinguishes a live incident from a procedural question. The evaluation approach is split into Depiction (what kind of content is being reviewed), Request (the precise question to answer), and Guidance (the reasoning framework). Safe content explicitly defines benign cases that contain policy keywords but are not violations, which prevents over-blocking. Training examples, around five to seven, anchor the probe’s reasoning on edge cases. Violations are organised by severity so downstream systems can respond proportionally. Ambiguity handling tells the probe what to do when a case sits in the grey zone.
5. How quickly can enterprises update AI safety policies when regulations or business rules change?
With traditional custom-classifier workflows, updates take months. By the time a new classifier is labelled, trained, evaluated, and signed off, the underlying policy has often moved on. A new regulation has dropped, a legal interpretation has shifted, or an HR definition has expanded. With custom probe authoring in Bud AI Foundry, the distance from policy decision to enforced behaviour is measured in minutes, not quarters. When a regulation changes or an incident review produces a new interpretation rule, the probe is updated the same week. This collapses the time tax that has historically made enterprise guardrails feel like a drag on responsiveness, and turns the safety layer into a live expression of current policy rather than a snapshot of last quarter’s rules.




.png)