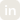In 2025, enterprises invested $684 billion in AI. More than $547 billion of that — over 80% — failed to deliver the business value it was meant to. MIT NANDA, after studying 300 deployments and interviewing 150 executives, found that 95% of GenAI pilots produced zero measurable P&L impact. S&P Global reported 42% of companies abandoning the majority of their AI initiatives, more than double the figure from a year earlier.
The natural reaction is to look for an explanation in the obvious places. Maybe the technology is too new. Maybe the use cases are too ambitious. Maybe the data is not ready. Each contains a grain of truth and all of them miss the actual mechanism. The models work. They demonstrably work, at the same enterprises, in the same hands, on the same data, when an individual researcher prototypes against a frontier API in a Jupyter notebook. The thing that fails — consistently, structurally, at scale — is everything around the model.
Forty to fifty-six independent tools. Seven infrastructure layers. Five lifecycle phases. Each tool excellent at its narrow function, each speaking a slightly different dialect, each owning a slice of the pipeline that no single team owns end-to-end. That is where the $547 billion goes. Not into models that do not work. Into systems around models that cannot be made to work.
This essay is about why that pattern is structural rather than accidental, why the next generation of enterprise AI cannot be built out of best-of-breed parts, and what the architecture that finally compounds — rather than collapses — actually looks like.
The architecture of failure
A production GenAI deployment touches seven distinct layers on every request: hardware, training, inference and serving, data and knowledge, agent orchestration, security and governance, and the application layer the user sees. In a fragmented enterprise, those seven layers are stitched together from forty to fifty-six independent tools, drawn from a dozen vendors, each with its own API, its own data model, its own logging format, and its own update cadence. None of them share an internal representation. Each one is excellent inside its category boundary; none of them owns the joins.
The bill for that fragmentation is paid in four compounding taxes. The latency tax: every tool boundary adds two to ten milliseconds, and an agentic workflow with five to ten tool calls per cycle accumulates 100 to 1,200 milliseconds of pure infrastructure overhead per agent action. The accuracy tax: HuggingFace’s standard text-embeddings-inference engine has a 94% error rate at the eight-thousand-token contexts most enterprises actually use, corrupting every downstream component. At 95% per-step accuracy across five steps, end-to-end accuracy collapses to 77%. The token tax: every boundary serialises, transmits, and re-serialises the same context, inflating token spend by 40 to 60% with nothing intelligent in return. And, most expensively, the oversizing tax: when the pipeline is noisy enough, the only lever left is to throw a frontier model at a task a 7B small language model could have handled cleanly — a 10 to 50x cost multiplier per query, attributed to the wrong line on the budget.
These four taxes compound on every request. Layered on top of them sits a fifth, structural one: the eight to twelve specialists, at $120K to $200K each, an enterprise has to staff just to hold the stack together — $1M to $2.4M a year before a single line of business logic is written. None of this is visible in any individual vendor’s pricing. All of it shows up at the system level.
The deeper failures
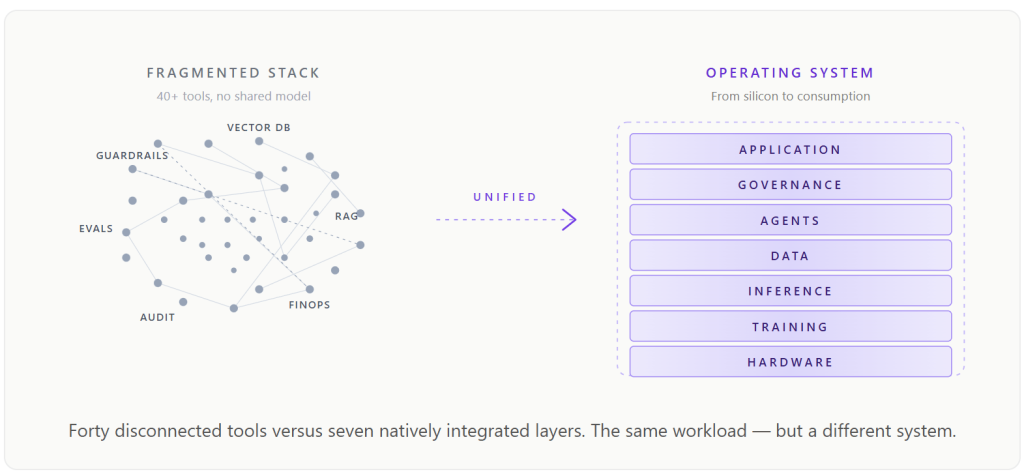
Even when an enterprise grinds through the integration cost and ships a pilot, two further failures sit waiting downstream. The first is the lifecycle problem. Enterprise AI is not the act of deploying a model; it is a five-phase journey that every agent has to make. Most projects die not within any one phase but at the transitions between them — the points where the tools that suit one phase cannot carry to the next.
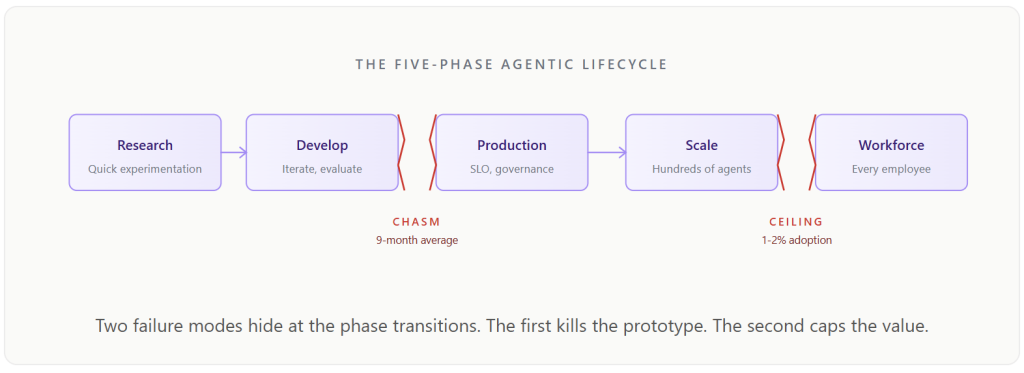
The first chasm sits between development and production. The prototype ran beautifully on a managed sandbox — Jupyter notebook, frontier API, hand-curated data — but the development tools do not transfer, the prompts behave differently under load, the evaluation metrics do not map. The whole system has to be rebuilt against different infrastructure, by different people, against different assumptions. MIT NANDA put the average bridge time at nine months. Many enterprises never cross.
The second is more subtle. Even the projects that reach production stall at 1 to 2% workforce adoption. 70% of employees keep using shadow AI in the meantime. The reason is not change management. It is a paradigm error. Enterprises instinctively apply the traditional software pattern to AI — IT builds, employees consume — and the pattern is wrong, because agents are not software applications. They are encoded expertise. The value of a customer support agent does not come from its technical architecture; it comes from the domain knowledge it embodies, which lives in the support rep who has spent years learning it, not in the AI team. Until the platform offers a creation surface where any employee can describe a workflow in plain English and deploy a governed production agent, the most valuable institutional knowledge in the enterprise stays trapped in people’s heads.
The operating system insight
The historical analogue is exact. Before SAP, enterprise software was fragmented — separate tools for finance, HR, supply chain, procurement, each excellent at its narrow function, each requiring custom integration, each producing a stack that nobody fully owned. SAP’s insight was that the integration itself was the product. Once the integration became native, the stack ceased to be a stack and became a system. GenAI is at exactly that moment now.
What enterprises actually need is not another guardrail vendor, another inference engine, another agent framework, another vector database. They need an operating system that owns the full stack from silicon to consumption — one shared data model, one unified trace, one governance posture, one cost line, one SLO owner. The components stop being puzzle pieces because there is no longer a puzzle to solve. The right unit of analysis stops being “which tool is best in its category” and starts being “which architecture lets every layer communicate the signals required for the system to keep getting better.”
The flywheel that fragmented stacks cannot run
The most consequential thing a unified platform makes possible is not a single optimisation. It is a compounding loop — and it is the part of the architecture that no fragmented stack can replicate, no matter how good its individual components are.
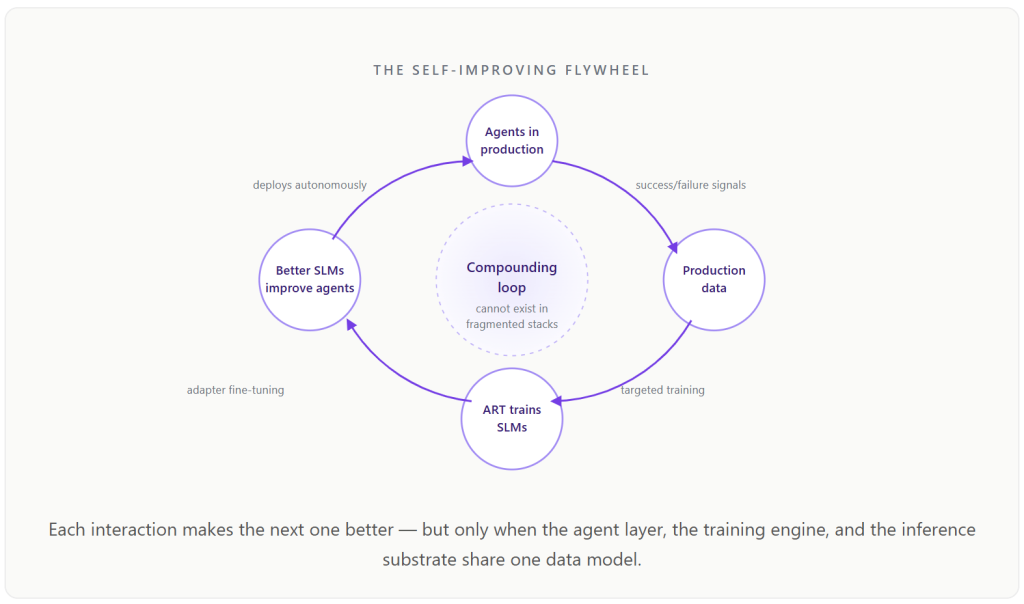
The mechanic is straightforward. Agents run enterprise workflows in production and generate data on which tasks succeed, which fail, and where accuracy gaps sit. A continuous-learning engine — what Bud calls Agentic Reinforcement Learning Training, or ART — captures those signals, generates targeted training data, performs adapter-based fine-tuning on domain small language models, evaluates against thresholds, and promotes improved models to production without human intervention. The improved SLMs feed back into the agent layer. Better agents generate better training data. Memory systems accumulate institutional knowledge that persists across sessions and users, so every employee interaction contributes to the organisation’s collective AI capability.
This loop cannot spin in a fragmented stack. Not because the components are individually weak, but because the agent framework, the training platform, the inference engine, and the governance system are separate tools with no shared data model. They cannot communicate the signals required for continuous improvement. In a unified platform, they are the same plane, and the signals move freely.
The economic consequence is the inversion of the cost curve most enterprises currently experience. In a fragmented stack, every new use case adds linear cost — more integration, more engineering, more tool sprawl. In a unified platform, every new use case adds production data that improves the SLMs that improve the agents that produce more production data. Marginal cost falls over time. Marginal capability rises. Over a 24-month horizon, that is not a feature difference. It is a compounding moat.
What the architecture actually delivers
The case stops being abstract once measured outcomes are on the table. A production retail-fashion deployment moved from $218,000 to $40,000 a month — 80% cost reduction at maintained accuracy — by collapsing its fragmented stack onto a unified platform. Independent Infosys TCO analysis put the same architecture 87.6% cheaper than GPT-4o on RAG, 90.7% cheaper on translation, and 76% cheaper on natural-language-to-SQL at 95% accuracy. CPU-native guardrails run at 8.39 milliseconds on a laptop — 2.3 times faster than competitors on a $15,000 A100 — at $0.10 per million classifications against $24 on GPU. Embedding error rates sit below 1%, against industry-standard 94% on TEI and 37% on Infinity.
The lifecycle numbers shift more dramatically still. A customer support agent that takes 16 to 20 weeks and 8 to 12 engineers in a fragmented stack ships in 5 to 7 days with 2 to 3 engineers. A multi-agent financial analysis workflow with MNPI sensitivity that takes 6 to 9 months and 20 to 25 components ships in 3 to 5 weeks. A sovereign government deployment that takes 12 to 18 months on $100K to $500K of GPU procurement — assuming chips are even available under export controls — ships in 4 to 8 weeks on the CPUs the government already owns. Three engineers, on a unified platform, are routinely delivering what previously required fifteen.
None of these numbers come from a better model. They come from removing the integration overhead that the rest of the industry has been paying as a hidden tax.
The integration is the product
Every enterprise that has tried to deploy GenAI seriously has, sooner or later, run into the same wall. The pilots work. The production systems do not. The infrastructure is too complex, the costs are two to four times what was forecast, the governance does not survive an audit, the agents fail in ways nobody can diagnose, the chasm between development and production consumes another nine months, and the team is exhausted by integration work that produces no business value. The 95% failure rate, viewed from inside any individual programme, is not surprising at all.
The temptation, having lived that experience, is to look for one more tool that will fix the bit that is currently broken. That instinct is the trap. The bit that is currently broken is downstream of the same structural problem that broke the last bit, and that will break the next one. Adding another excellent tool to a forty-tool stack is, on the evidence, a way to make the system worse.
The market is not missing intelligence. It is missing an operating system — the unified infrastructure that owns the full stack from silicon to consumption, that makes AI deployable, governable, affordable, and portable as a single coherent system rather than a collection of best-of-breed parts. The enterprises that build on that operating system will capture the compounding returns the other 95% are leaving on the table. Not because their models are better. Because their systems work.
The integration is the product. That was true for SAP forty years ago. It is true for GenAI now.




.png)