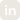
In the early days of computing, machines came without an operating system. Users had to install one themselves, often requiring technical know-how. That changed in the 1990s, when operating systems like Windows and macOS began shipping preinstalled. This shift transformed the user experience—making computers easier to use out of the box, expanding access to non-technical users, and enabling tighter integration between hardware and software. It also gave developers a stable platform to build on, accelerating the growth of rich software ecosystems. Ultimately, preinstalled OSes helped push computing into the mainstream, turning complex machines into everyday tools for work, learning, and life.
Today, we’re entering a similar transition—this time with AI. Just as early computers were shipped as raw hardware, many devices today come with raw compute power but little intelligence. That, too, is starting to change. We’re on the cusp of “AI in a box”: intelligent systems shipping with built-in AI capabilities, ready to use right out of the gate.
What is AI in a box?
“AI-in-a-Box” refers to a pre-integrated, ready-to-deploy solution that combines all the core components required to run artificial intelligence workloads. Instead of building an AI stack from scratch—sourcing separate hardware, configuring infrastructure, setting up software environments, and integrating various tools—organizations can deploy a single, consolidated system that comes with everything pre-installed, tested, and supported.
These solutions typically include compute hardware like CPUs and GPUs, high-speed storage, networking, and a full software stack consisting of AI models, agents, data processing tools, orchestration platforms like Kubernetes or OpenShift, and monitoring or security services. The goal is to minimize the complexity and time required to get AI projects off the ground.
AI-in-a-Box is often used in on-premises or private cloud environments, especially where data privacy, regulatory compliance, or latency is a concern. Organizations in sectors like healthcare, finance, or government may prefer these systems because they offer greater control and data sovereignty compared to public cloud services.
In essence, AI-in-a-Box simplifies deployment by offering a turnkey system—just plug it into your environment and start working on AI applications. It removes the need for deep infrastructure expertise and accelerates the path from development to production.
How Bud AI foundry enables OEMs to Ship AI-Native Devices at Scale
Shipping AI-ready hardware isn’t just about adding a GPU or running a few pre-trained models. It requires an integrated AI infrastructure stack that bridges silicon, runtime, security, orchestration and all the way to the user experience layer. This is where Bud AI Foundry comes in. A unified platform that transforms OEM hardware into an AI-native product line, ready for deployment, management, and continuous evolution.
1. From Compute-Ready to AI-Ready: The New OEM Baseline
AI-enabled devices demand AI-native firmware and runtime support that make them inference-ready out of the box. Bud AI Foundry introduces this through its Bud Runtime, a universal inference engine that abstracts away hardware complexity. It automatically optimizes models for CPUs, GPUs, HPUs, and even emerging accelerators, ensuring that every device, regardless of configuration, can serve AI models efficiently from day one. Key Capabilities for OEMs
- Universal Model Support: LLMs, diffusion models, speech, and vision — all run under the same runtime.
- Self-Healing Runtime: Autonomous recovery and rollback, guaranteeing reliability in field-deployed devices.
- Heterogeneous Parallelism: Split inference workloads intelligently across different compute units for optimal utilization.
- Zero-Config Deployments: Each device automatically tunes its AI stack based on its hardware profile, eliminating post-shipment configuration.
With Bud Runtime, OEMs can ship devices that “wake up AI-capable” the moment they’re powered on.
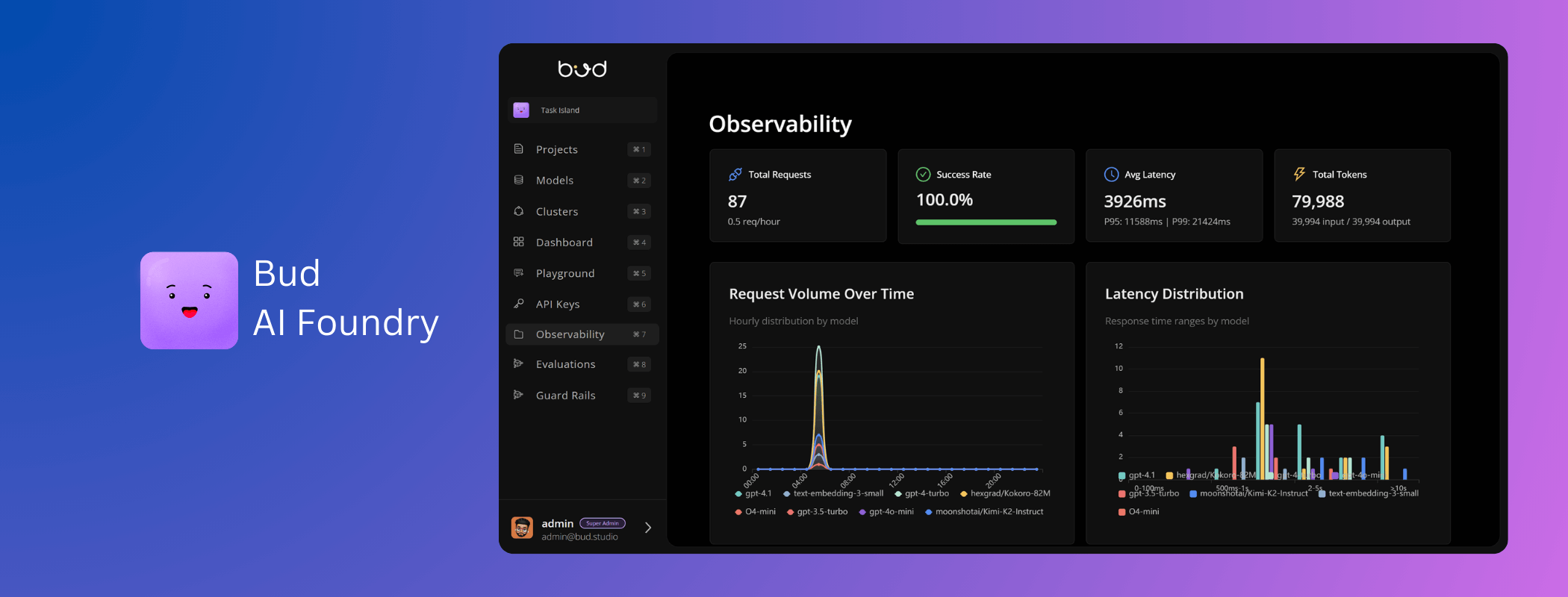
2. Pre-Trained Intelligence: Model Zoo and Agent Runtime Onboard
AI-enabled devices aren’t valuable because they can run AI — they’re valuable because they can apply AI immediately. To enable that, Bud AI Foundry provides a built-in Model Zoo and pre-built domain specific AI agents that OEMs can preload during manufacturing.
Model Zoo offers a curated repository of optimized foundation models (language, vision, speech, and multimodal) pre-validated to run on a variety of hardware tiers. OEMs can:
- Embed the Model Zoo within device firmware for offline or edge inference.
- Enable customers to download and deploy updated or specialized models via OTA updates.
- Ensure all models are runtime-compatible and security-scanned by Bud Sentinel before shipping.
The Bud AI foundry’s Agent Runtime provides the orchestration layer that lets devices run autonomous or user-facing AI agents locally. Built on a distributed microservice foundation, it supports:
- Agent-as-a-Service models for device ecosystems
- Tool Guardrails to ensure every AI-driven interaction stays safe and policy-compliant.
- Dynamic scaling and orchestration, so agents can adapt to resource availability and task priority.
For OEMs, this means each device becomes part of a network of intelligent endpoints, rather than a static hardware node.
3. Integrated AI Security: Guardrails from Silicon to Cloud
When AI models are embedded at the edge, security cannot be bolted on — it must be foundational. Bud AI Foundry integrates Bud Sentinel, a zero-trust AI security suite that OEMs can embed directly into their system images. Key Features are;
- Sub-10ms Guardrail Enforcement: Ultra-low-latency scanning for prompt injection, data leakage, or unsafe model responses.
- Multi-Layered Protection: Regex, ML classifiers, and LLM-based filters operating simultaneously to protect user data and model integrity.
- Custom OEM Policies: Manufacturers can define proprietary compliance and ethical policies using symbolic AI rules.
- Confidential Computing Ready: Support for Intel, Nvidia, and ARM trusted execution environments for future-proof device compliance.
Bud Sentinel ensures every AI-enabled device is secure by design, protecting both the user and the OEM brand reputation.
4. Intelligent Scaling and OTA Evolution
Bud AI Foundry’s Bud Scaler offers OEMs a distributed scaling and optimization engine. It delivers several key capabilities that fundamentally change how AI is deployed and maintained across distributed systems.
One of its core features is SLO-aware scaling, which automatically adjusts inference or agent workloads based on defined service-level objectives such as latency, cost constraints, or battery usage profiles. This ensures consistent performance across a wide range of devices and operating conditions. Bud Scaler also supports auto routing, enabling dynamic distribution of workloads between on-device resources and cloud endpoints. This flexibility allows the system to select the best execution path based on performance requirements or resource availability.
In addition, the platform provides real-time observability into model performance, latency metrics, and the overall health of devices across potentially thousands of endpoints. This insight helps OEMs monitor, troubleshoot, and optimize their AI deployments at scale.Another important capability is cost and energy optimization. Bud Scaler incorporates built-in feedback loops that continuously tune workloads for optimal performance per watt, a critical factor in mobile and embedded environments where power efficiency is essential.
By enabling these functions, Bud Scaler transforms the traditional OEM model from a static “ship and forget” approach to a dynamic “ship and evolve” strategy. This shift allows for continuous AI improvement and adaptation throughout the entire product lifecycle.
5. Bud Studio for Custom Agents
AI devices are no longer single-purpose. Manufacturers, developers, and even end-users expect the ability to build and personalize AI experiences. Bud Studio extends this flexibility to OEM ecosystems through a no-code and low-code interface for AI creation. For OEMs and Ecosystem Partners
- White-Labeled AI Studio: Let customers or developers build custom agents and workflows on your devices.
- Enterprise RBAC & SSO: Full control over user roles, permissions, and integrations.
- Multi-Tenant AI PaaS: Support for both consumer and enterprise product lines.
This enables OEMs to offer AI-as-a-Feature — not just hardware, but a living AI platform customers can extend, personalize, and monetize.
6. The Endgame: Shipping an AI-Native Product Line
With Bud AI Foundry, OEMs can go beyond building “AI-compatible” devices — they can build AI-native ecosystems. Each component of the Foundry—from the Runtime and Scaler to Sentinel and Studio—ensures that every device:
- Ships with pre-integrated AI capabilities.
- Remains secure, observable, and adaptive.
- Evolves continuously through OTA model and agent updates.
- Enables end-users to become co-creators of intelligence.
In essence, Bud AI Foundry allows OEMs to turn hardware into living AI platforms, delivering not just machines, but thinking systems ready for the AI-driven future.







.png)