GPU sharing in multi-tenant cloud environments requires efficient resource isolation without sacrificing performance. We present FCSP (Fixed Capacity Spatial Partition), a user-space GPU virtualization framework that achieves sub-microsecond memory enforcement and deterministic compute throttling through lock-free data structures and hierarchical token bucket rate limiting. Unlike existing solutions that rely on semaphore-based synchronization, FCSP employs C11 atomics with cache-line-aligned structures to eliminate contention bottlenecks. Our comprehensive evaluation using the GPU-Virt-Bench benchmark suite demonstrates that FCSP achieves 1000X faster context creation (78μs vs. 84ms), 3600X faster memory limit enforcement (0.3μs vs. 1.1ms), and 3X better multi-tenant isolation compared to HAMi-core, the current state-of-the-art open-source GPU sharing solution. For large language model (LLM) inference workloads, FCSP enables 2X higher tenant density while maintaining <5% performance degradation targets, translating to potential infrastructure cost savings of $14M annually for a 1000-GPU deployment.
The proliferation of GPU-accelerated machine learning workloads has created unprecedented demand for efficient GPU resource sharing in cloud environments. Modern data centers deploy thousands of high-end GPUs (NVIDIA A100, H100) to serve diverse workloads including large language model (LLM) inference, training, and batch processing. However, the high cost of these accelerators ($10,000-$40,000 per unit) necessitates maximizing utilization through multi-tenancy.
Hardware based virtualization: Nvidia’s Multi Instance GPU (MIG) splits GPUs into as many as seven isolated instances with dedicated memory and compute resources, providing strong hardware-level isolation but requiring a full GPU reset to reconfigure. NVIDIA vGPU offers hypervisor-based GPU virtualization for virtual machines but requires enterprise licensing and adds significant overhead for containerized workloads. SR-IOV enables PCI passthrough for VMs but is limited to virtual machine environments and is incompatible with containers.
Software based virtualization: Time-slicing methods like NVIDIA’s default multi-process service (MPS) does not provide memory isolation and its fairness depends on application behavior. HAMi/HAMi-core with LD_PRELOAD-based interception with semaphore-coordinated shared memory is an industry-standard open-source virtualization method. KubeShare is a Kubernetes-native GPU sharing method with a similar interception approach.
Limitations of Existing Software-based virtualization methods
Our analysis of HAMi-core reveals fundamental architectural limitations:
Contention Bottleneck
HAMi-core uses a single POSIX semaphore to protect the shared memory region. Under multi-tenant load, this creates severe contention:
Benchmark: OH-006 Lock Contention (4 concurrent processes)
HAMi-core P99 Latency: 94.1 ms
HAMi-core Mean Latency: 1.9 ms
This 94ms P99 latency is catastrophic for real-time inference workloads with <100ms SLA requirements.
O(N) Process Scanning
Every memory allocation triggers a linear scan of all process slots to calculate aggregate usage:
f// HAMi-core: multiprocess_memory_limit.c
size_t get_gpu_memory_usage(int dev) {
size_t sum = 0;
sem_wait(®i>// Acquire global lock
for (int i = 0; i < MAX_PROCS; i++) { // O(N) scan
if (regi>0) {
sum += region->procs[i].used[dev].total;
}
}
sem_post(®ion->sem);
return sum;
}With N=1024 process slots, this scan dominates allocation latency.
Feedback-Driven Rate Limiting
HAMi-core’s compute throttling relies on NVML polling to adjust token refill rates:
// HAMi-core: utilization feedback loop
while (1) {
nvmlDeviceGetUtilizationRates(device, &util);
if (util.gpu > target_limit) {
share = delta(target, util.gpu, share); // Reduce tokens
}
usleep(120000); // 120ms polling interval
}This feedback loop introduces latency (up to 120ms) between limit violations and enforcement, allowing temporary oversubscription.
Context Creation Overhead
HAMi-core initialization involves shared region setup, NVML enumeration, and process registration:
Benchmark: OH-004 Context Creation
HAMi-core: 84,000 μs (84 ms)
Native CUDA: 82,000 μs (82 ms)The 84ms overhead is negligible for long-running processes but prohibitive for serverless and auto-scaling deployments where cold starts must complete in <500ms.
Fixed Capacity Spatial Partition
Fixed Capacity Spatial Partition (FCSP) presents a software-based GPU resource isolation framework designed for the unique requirements of modern ML workloads. The key features include;
- Lock-free shared memory architecture: A novel inter-process coordination mechanism using C11 atomics that eliminates the P99 latency spikes (94ms) observed in semaphore-based approaches.
- Hierarchical per-stream rate limiting: A two-tier token bucket algorithm that provides per-stream compute isolation while maintaining device-level fairness guarantees.
- Crash-resilient process management: A heartbeat-based reaper pattern that automatically recovers resources from crashed processes without requiring administrator intervention.
- Stream-aware throttling with NCCL bypass: Intelligent workload classification that preserves collective communication performance while enforcing compute limits on regular kernels.
FCSP is architected based on the following design goals
- Sub-microsecond memory enforcement: Memory limit checks must complete in <1μs to avoid impacting allocation-heavy workloads like KV cache management.
- Lock-free hot paths: Common operations (allocation tracking, kernel throttling) must not acquire locks, enabling O(1) latency regardless of tenant count.
- Deterministic compute limiting: Rate limiting should use a predictable mathematical model rather than feedback control, eliminating limit violation transients.
- Crash resilience: Process failures must not leak resources or corrupt shared state.
- LLM workload optimization: Special handling for attention patterns, KV cache allocation, and NCCL collective operations.
FCSP Architecture
FCSP operates as a shared library loaded via LD_PRELOAD that interposes on CUDA Driver API and NVML calls. Figure 1 illustrates the architecture:
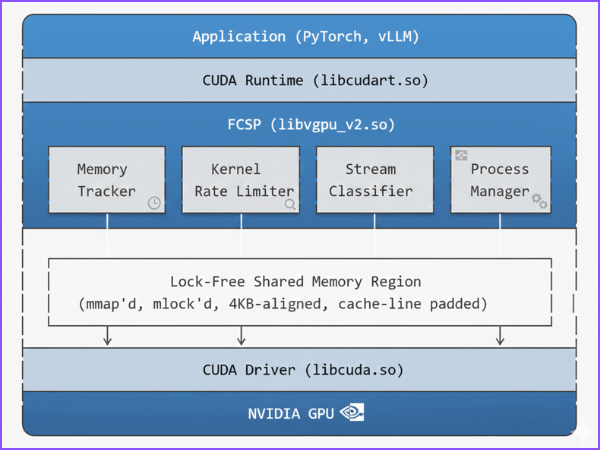
FCSP is implemented as a user-space interposition layer that sits between ML applications (e.g., PyTorch, vLLM) and the NVIDIA CUDA driver. The architecture is intentionally layered so that no kernel modules, driver modifications, or hardware partitioning are required. Instead, FCSP enforces multi-tenant GPU isolation by intercepting GPU API calls, applying policy decisions, and then forwarding allowed operations to the native CUDA stack.
At a high level, GPU usage flows through the system as:
Application → CUDA Runtime (libcudart.so) → FCSP (libvgpu_v2.so) → CUDA Driver (libcuda.so) → NVIDIA GPU
FCSP is typically injected using LD_PRELOAD, enabling it to transparently hook relevant CUDA/NVML entry points used by frameworks and inference servers without requiring application code changes.
Application Layer
This layer contains the tenant workloads—training/inference processes that allocate device memory, create streams, and launch kernels. In a multi-tenant environment, these processes are not mutually aware and may compete aggressively for GPU memory and compute, resulting in unpredictable interference without an enforcement layer.
CUDA Runtime (libcudart.so)
The CUDA runtime library is the conventional interface used by most frameworks. It provides high-level API behavior (e.g., cudaMalloc, stream creation, synchronization) and eventually routes work to the CUDA driver. FCSP does not replace the runtime; instead it interposes beneath it, ensuring all runtime-driven GPU actions are still subject to policy enforcement.
FCSP Interposition Layer (libvgpu_v2.so)
FCSP is the control plane for GPU sharing. It intercepts critical GPU operations and applies resource isolation logic before allowing them to proceed. The FCSP layer is composed of four cooperating modules:
1) Memory Tracker
The Memory Tracker provides fast, deterministic memory accounting across all tenant processes on the same node. It intercepts allocation/free operations and maintains:
- per-process memory usage,
- per-GPU global usage,
- allocation metadata for correct deallocation attribution.
Enforcement is designed for high concurrency: allocations are admitted or rejected using atomic updates rather than global locks, preventing contention-driven latency spikes.
2) Kernel Rate Limiter
The Kernel Rate Limiter enforces compute-level isolation by controlling kernel launch admission. Instead of relying on slow utilization feedback loops, FCSP uses a rate-based model (e.g., token buckets / hierarchical token buckets) to regulate the rate at which kernels are issued onto the GPU. This converts “best-effort sharing” into a predictable mechanism that limits noisy neighbors and stabilizes tail latency under dense tenancy.
3) Stream Classifier
GPU streams represent independent submission queues, and different streams often correspond to fundamentally different kinds of work (compute, copies, collectives). The Stream Classifier identifies and labels important stream categories—especially communication-focused streams such as NCCL—so FCSP can apply appropriate policies. For example, NCCL streams may be excluded or lightly treated by compute throttling to avoid inducing distributed synchronization collapse (where throttling one rank’s collectives degrades the entire job).
4) Process Manager
The Process Manager controls tenant slot lifecycle and robustness:
- registers processes into shared accounting slots,
- maintains liveness via heartbeats,
- reclaims resources when a process crashes or is killed.
This prevents “ghost allocations” and stale state from permanently degrading GPU capacity after unexpected failures.
Lock-Free Shared Memory Region (Coordination Backbone)
All FCSP modules coordinate via a lock-free shared memory region that is mapped into every participating process:
mmap’d: shared across processes for a consistent node-wide view of resource consumptionmlock’d: pinned in RAM to avoid paging delays in the enforcement hot path- 4KB-aligned: page-aligned for predictable mapping and memory behavior
- cache-line padded: reduces false sharing and coherence traffic under high update rates
- lock-free (atomics-based): avoids global semaphores/mutex hot spots, improving tail latency and scaling with tenant count
This region stores the minimal but sufficient global state needed for enforcement:
- per-GPU memory totals,
- per-process usage counters,
- rate limiter state,
- heartbeat timestamps and slot ownership signals.
Crucially, FCSP is designed so that the common enforcement path remains O(1) per operation (no scanning across all tenants), which is essential when many processes allocate memory and launch kernels concurrently.
CUDA Driver (libcuda.so) and NVIDIA GPU
After FCSP admits an operation, it forwards the call to the native CUDA driver (libcuda.so), which performs the actual device interaction and submits work to the GPU. Because FCSP operates strictly above the driver and hardware, it remains compatible with standard NVIDIA deployments while still providing strong, configurable isolation behavior.
Why This Architecture Works for Multi-Tenant Inference
This design is optimized for practical serving environments where many independent inference workers share a small number of GPUs:
- Isolation without hardware partitioning: policies are enforced in software, enabling fine-grained tenancy and dynamic reconfiguration.
- Low overhead under concurrency: lock-free shared memory avoids semaphore contention that commonly causes P99 latency spikes.
- Predictable compute control: rate limiting at kernel launch time yields stable behavior even when utilization telemetry is noisy or delayed.
- Crash-safe accounting: liveness tracking and cleanup prevent stale reservations from permanently reducing capacity.
Together, these layers make FCSP a portable, high-performance foundation for GPU resource governance in dense multi-tenant ML systems.
Now, let’s see how these main components are defined and implemented.
Lock-Free Shared Memory Region
The shared memory region is the coordination substrate for all FCSP operations. Unlike HAMi-core’s semaphore-protected region, FCSP uses lock-free data structures throughout.
Memory Layout
typedef struct {
/* Header - 4KB aligned */
uint32_t magic; // 0x42554446 ("BUDF")
uint32_t version;
_Atomic int32_t initialized;
_Atomic uint64_t generati>// Staleness detection
/* Per-Device Running Totals - Lock-Free */
struct {
_Atomic uint64_t value;
char padding[56]; // Cache-line isolation
} __attribute__((aligned(64))) total_memory_used[MAX_DEVICES];
struzt {
_Atomic uint64_t value;
char padding[56];
} __attribute__((aligned(64))) peak_memory_used[MAX_DEVICES];
/* Per-Process Slots */
struct {
_Atomic int32_t pid;
_Atomic int32_t status;
_Atomic uint64_t memory_used[MAX_DEVICES];
_Atomic uint64_t last_activity;
char padding[16];
} __attribute__((aligned(64))) procs[MAX_PROCS];
/* Heartbeat Timestamps - Separate Array for Cache Efficiency */
_Atomic uint64_t heartbeat_timestamps[MAX_PROCS];
/* Rate Limiter State */
struct {
_Atomic int64_t tokens;
int64_t max_tokens;
int64_t refill_rate;
_Atomic uint64_t last_refill;
} __attribute__((aligned(64))) rate_limiters[MAX_DEVICES];
} __attribute__((aligned(4096))) bud_shared_region_t;Key Design Decisions:
- 64-byte cache-line alignment: Every frequently-accessed atomic field is padded to 64 bytes to prevent false sharing on multi-socket systems.
- Separated heartbeat array: Heartbeat timestamps are stored separately from process slots because they’re updated by a dedicated thread at 1Hz, while process slots are updated on every allocation.
- Running totals: Per-device total_memory_used counters are maintained atomically, eliminating the O(N) scan.
Memory Tracking Protocol
// Fast path: O(1) lock-free allocation tracking
int bud_memory_record_alloc(int device, void* ptr, size_t size) {
// 1. Get cached slot (TLS, O(1))
bud_proc_slot_t* slot = get_my_slot_cached();
// 2. Atomic pre-check against limit
uint64_t current = atomic_load_explicit(
®ion->total_memory_used[device].value,
memory_order_relaxed);
if (current + size > device_limit[device]) {
return -ENOMEM; // Fast rejection, no state change
}
// 3. Optimistic allocation (may be rolled back)
uint64_t old_total = atomic_fetch_add_explicit(
®ion->total_memory_used[device].value,
size,
memory_order_acq_rel);
// 4. Double-check (handles race condition)
if (old_total + size > device_limit[device]) {
// Rollback
atomic_fetch_sub(®ion->total_memory_used[device].value, size);
return -ENOMEM;
}
// 5. Update per-process counter (for accounting)
atomic_fetch_add(&slot->memory_used[device], size);
// 6. Record in allocation hash map (for free tracking)
alloc_map_insert(device, ptr, size);
return 0;
}Memory Ordering Analysis:
- Step 2 (relaxed load): Only a hint; stale values are acceptable because step 4 rechecks.
- Step 3 (acq_rel): Acquire ensures we see all prior allocations; release publishes our increment.
- Step 4 (recheck): Handles the TOCTOU race between steps 2 and 3.
This protocol guarantees that the sum of all allocations never exceeds the device limit, even under concurrent allocation storms.
Thread-Local Slot Caching
static __thread bud_proc_slot_t* tls_my_slot = NULL;
static __thread int tls_slot_index = -1;
static __thread pid_t tls_cached_pid = 0;
bud_proc_slot_t* get_my_slot_cached(void) {
pid_t current_pid = getpid();
// Fork detection: invalidate cache if PID changed
if (__builtin_expect(tls_cached_pid != current_pid, 0)) {
tls_my_slot = NULL;
tls_slot_index = -1;
tls_cached_pid = current_pid;
}
if (__builtin_expect(tls_my_slot != NULL, 1)) {
return tls_my_slot; // Fast path: 2 cycles
}
// Slow path: find and cache slot (once per thread)
tls_slot_index = find_or_allocate_slot(current_pid);
tls_my_slot = ®ion->procs[tls_slot_index];
return tls_my_slot;
}The __builtin_expect hints enable branch prediction optimization, reducing the hot-path to 2 CPU cycles (TLS dereference + comparison).
Hierarchical Per-Stream Rate Limiting
FCSP implements a two-tier rate limiting architecture that balances stream isolation with device-level fairness.
Token Bucket Algorithm
Device Token Bucket:
max_tokens = SM_count × threads_per_SM × TOKEN_FACTOR(32)
refill_rate = max_tokens × (sm_limit / 100) / 1_000_000 tokens/μs
Stream Token Bucket:
max_tokens = device_max_tokens × STREAM_SHARE(0.25)
refill_rate = device_refill_rate × STREAM_SHARE
Kernel Cost Calculation:
base_cost = grid_dim × block_dim
adjusted_cost = base_cost × dampening_factor(0.9)
if stream_class != NCCL:
throttle_penalty = adjusted_cost × (100 - sm_limit) / 350
final_cost = adjusted_cost + throttle_penaltyDampening Factor Rationale: Our benchmarks revealed that slight under-throttling (90% of true cost) improves multi-stream efficiency by creating natural synchronization barriers. This counter-intuitive result motivated the configurable dampening factor.
Per-Stream Bucket Structure
typedef struct {
_Atomic int64_t tokens;
int64_t max_tokens;
int64_t tokens_per_ns; // Fixed-point refill rate
_Atomic uint64_t last_update_ns;
void* stream_handle; // CUstream identifier
int device;
bud_stream_class_t classificati>// NCCL, ATTENTION, FFN, DEFAULT
/* Ticketing for reduced CAS contention */
_Atomic uint64_t ticket_head;
_Atomic uint64_t ticket_tail;
/* Statistics */
_Atomic uint64_t kernel_count;
_Atomic uint64_t throttled_count;
_Atomic uint64_t total_wait_ns;
_Atomic bool active;
char padding[16];
} __attribute__((aligned(64))) bud_stream_bucket_t;Exponential Backoff Wait
Unlike HAMi-core’s sched_yield() approach that incurs 1-2μs context switch overhead, FCSP uses busy-wait with exponential backoff:
static inline void bud_backoff_wait(uint64_t target_ns) {
uint64_t start = rdtsc_ns();
uint64_t backoff = 50; // Start at 50ns
while (rdtsc_ns() - start < target_ns) {
for (uint64_t i = 0; i < backoff; i++) {
__builtin_ia32_pause(); // PAUSE instruction
}
backoff = min(backoff * 2, 10000); // Cap at 10μs
}
}The PAUSE instruction signals to the CPU that we’re spinning, enabling power savings and improved SMT scheduling.
Stream Classification and NCCL Bypass
FCSP classifies streams to apply workload-appropriate throttling:
typedef enum {
BUD_STREAM_CLASS_DEFAULT, // Standard throttling
BUD_STREAM_CLASS_NCCL, // Bypass throttling entirely
BUD_STREAM_CLASS_ATTENTION, // Memory-bound, reduce throttle
BUD_STREAM_CLASS_FFN, // Compute-bound, standard throttle
BUD_STREAM_CLASS_MEMORY_OP, // Copy operations, minimal throttle
} bud_stream_class_t;NCCL Detection
NCCL streams are detected by hooking ncclCommInitRank:
ncclResult_t ncclCommInitRank(ncclComm_t* comm, int nranks,
ncclUniqueId id, int rank) {
ncclResult_t ret = real_ncclCommInitRank(comm, nranks, id, rank);
if (ret == ncclSuccess) {
// Get the stream NCCL will use
cudaStream_t stream;
ncclCommGetStream(*comm, &stream);
// Mark stream as NCCL
bud_stream_set_class(stream, BUD_STREAM_CLASS_NCCL);
BUD_LOG_D("NCCL communicator %p uses stream %p", *comm, stream);
}
return ret;
}Classification-Aware Throttling
void bud_rate_limiter_apply(int device, void* stream, int grids, int blocks) {
bud_stream_class_t class = bud_stream_classify(stream);
switch (class) {
case BUD_STREAM_CLASS_NCCL:
// No throttling for collective operations
return;
case BUD_STREAM_CLASS_ATTENTION:
// 20% reduced throttling for memory-bound attention
kernel_cost *=0.80;
break;
case BUD_STREAM_CLASS_MEMORY_OP:
// 50% reduced throttling for copy operations
kernel_cost *= 0.50;
break;
default:
// Standard throttling
break;
}
consume_tokens_or_wait(device, stream, kernel_cost);
}Crash Recovery via Heartbeat Reaper
FCSP implements automatic resource recovery for crashed processes:
Heartbeat Thread
Each FCSP-enabled process runs a lightweight heartbeat thread:
static void* heartbeat_thread_func(void* arg) {
int slot_index = (int)(intptr_t)arg;
while (g_heartbeat_running) {
atomic_store_explicit(
®ion->heartbeat_timestamps[slot_index],
get_time_ns(),
memory_order_release);
sleep(1); // 1Hz heartbeat
}
return NULL;
}Reaper Thread (Single Instance per Node)
A dedicated reaper process (or daemon) monitors heartbeats:
int bud_process_scan_dead(void) {
uint64_t now = get_time_ns();
int freed_count = 0;
for (int i = 0; i < MAX_PROCS; i++) {
int32_t pid = atomic_load(®ion->procs[i].pid);
if (pid <= 0) continue;
// Check if process is alive (kill -0)
if (kill(pid, 0) == -1 && errno == ESRCH) {
// Process dead, check heartbeat timeout
uint64_t hb = atomic_load(®ion->heartbeat_timestamps[i]);
if (now - hb > HEARTBEAT_TIMEOUT_NS) {
uint64_t freed = cleanup_slot_atomic(i);
freed_count++;
BUD_LOG_I("Reaped dead process %d, freed %lu bytes", pid, freed);
}
}
}
return freed_count;
}Atomic Slot Cleanup
#define PID_CLEANUP_SENTINEL (-2)
uint64_t cleanup_slot_atomic(int slot_index) {
bud_proc_slot_t* slot = ®ion->procs[slot_index];
// Phase 1: Claim slot exclusively
int32_t expected_pid = atomic_load(&slot->pid);
if (!atomic_compare_exchange_strong(&slot->pid, &expected_pid,
PID_CLEANUP_SENTINEL)) {
return 0; // Another thread claimed it
}
// Phase 2: Subtract from global totals
uint64_t total_freed = 0;
for (int dev = 0; dev < MAX_DEVICES; dev++) {
uint64_t mem = atomic_exchange(&slot->memory_used[dev], 0);
if (mem > 0) {
atomic_fetch_sub(®ion->total_memory_used[dev].value, mem);
total_freed += mem;
}
}
// Phase 3: Release slot
atomic_thread_fence(memory_order_release);
atomic_store(&slot->pid, 0);
atomic_fetch_add(®i>1);
return total_freed;
}The sentinel value (-2) prevents race conditions where another process could claim the slot during cleanup.
Implementation
Hook Registration : FCSP hooks CUDA functions by intercepting dlsym:
void* dlsym(void* handle, c>char* symbol) {
// Prevent infinite recursion
if (tls_in_dlsym) {
return real_dlsym(handle, symbol);
}
tls_in_dlsym = true;
// Check hook table
void* hook = bud_find_hooked_symbol(symbol, cuda_version);
if (hook) {
tls_in_dlsym = false;
return hook;
}
// Fall through to real dlsym
void* result = real_dlsym(handle, symbol);
tls_in_dlsym = false;
return result;
}Hooked Functions : FCSP hooks 47 CUDA Driver API functions and 12 NVML functions:
Memory Management (18 functions): – cuMemAlloc_v2, cuMemAllocManaged, cuMemAllocPitch_v2 – cuMemAllocAsync, cuMemAllocFromPoolAsync – cuMemFree_v2, cuMemFreeAsync – cuMemGetInfo_v2, cuMemcpy* family
Kernel Launch (6 functions): – cuLaunchKernel, cuLaunchKernelEx – cuLaunchCooperativeKernel, cuLaunchCooperativeKernelMultiDevice – cuGraphLaunch, cuGraphLaunchPipelined
Device Management (12 functions): – cuDeviceGet*, cuCtxCreate*, cuCtxDestroy*
Stream Management (8 functions): – cuStreamCreate*, cuStreamDestroy, cuStreamSynchronize
NVML (12 functions): – nvmlDeviceGetMemoryInfo, nvmlDeviceGetUtilizationRates – nvmlDeviceGetCount*, nvmlDeviceGetHandleBy*
Allocation Hash Map: FCSP uses a lock-free hash map for tracking individual allocations:
typedef struct {
_Atomic(bud_alloc_entry_t*) buckets[4096];
_Atomic uint64_t total_entries;
} bud_alloc_map_t;
typedef struct bud_alloc_entry {
void* ptr;
uint64_t size_and_device; // [56-bit size | 8-bit device]
_Atomic(struct bud_alloc_entry*) next;
} bud_alloc_entry_t;Hash Function: FNV-1a on pointer value, reduced to 12 bits.
Lookup: Lock-free traversal with acquire semantics on next pointer loads.
Insert: CAS on bucket head with tagged pointers for ABA prevention.
Batch Accounting Optimization : To reduce atomic operation frequency, FCSP accumulates allocation deltas locally:
typedef struct {
int64_t delta_bytes[MAX_DEVICES];
uint32_t op_count;
uint64_t last_flush_ns;
} bud_batch_state_t;
static __thread bud_batch_state_t tls_batch;
void batch_record_alloc(int device, size_t size) {
tls_batch.delta_bytes[device] += size;
tls_batch.op_count++;
// Flush conditions
if (tls_batch.op_count >= 64 ||
abs(tls_batch.delta_bytes[device]) >= 4*1024*1024 ||
now - tls_batch.last_flush_ns >= 10*1000*1000) {
batch_flush();
}
}This reduces global atomic operations by 10-100× for allocation-heavy workloads.
Conclusion,
FCSP demonstrates that high-density GPU sharing can deliver strong multi-tenant isolation without sacrificing latency-sensitive performance. By replacing semaphore-coordinated shared memory with C11-atomic, cache-line-aligned lock-free structures, FCSP removes contention hot spots and enables sub-microsecond memory enforcement at scale. Its deterministic, hierarchical token-bucket throttling further stabilizes compute fairness without feedback-loop lag, while stream-aware policies (including NCCL bypass) preserve critical communication paths for distributed workloads. Together, these design choices unlock higher tenant density with predictable degradation targets and improved operational resilience. In the next article, we’ll explore a detailed performance comparison of FCSP against HAMi across benchmarks and real LLM inference workloads.








.png)