We just open-sourced GPU-Virt-Bench, a comprehensive benchmarking framework for evaluating software-based GPU virtualization systems like HAMi-core, BUD-FCSP, and comparing against ideal MIG behavior. It evaluates 56 metrics across 10 categories.
Why Benchmark GPU-Virtualization Systems?
When several applications or tenants try to run on the same GPU, the system can become unstable and unpredictable. Instead of improving efficiency, shared access often introduces performance issues, fairness problems, and even reliability risks that are difficult to diagnose or control.
- Noisy-neighbour slowdowns — One workload can hog bandwidth or compute, causing others to run significantly slower.
- Unfair resource allocation — The GPU may not divide compute or memory evenly, giving some tasks more than they need while starving others.
- Poor performance for large models — Workloads like LLMs often degrade sharply under contention, failing to reach their expected throughput or latency.
- Incorrectly enforced limits — Memory or compute caps can be misapplied, letting processes exceed boundaries or throttling them too aggressively.
- System instability or crashes — When multiple competing tasks overload shared resources, the GPU driver or scheduler may fail, bringing down the entire system.
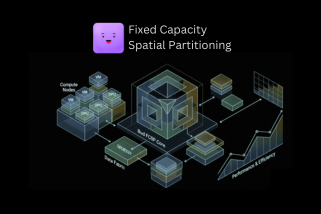
Different GPU virtualization frameworks exist to address these challenges, but none of them are universal—what delivers great performance on one system may behave poorly on another. GPU-Virt-Bench enables you to evaluate and compare these frameworks side-by-side, using consistent benchmarks. With it, you can choose the best virtualization approach for your deployment scenario, ensuring predictable performance, fair resource sharing, higher GPU utilization, and greater overall stability. Current version of GPU-Virt-Bench supports comparions between no virtualization (baseline), HAMi-core original implementation, BUD-FCSP improved implementation and Simulated ideal MIG behavior.
How it works.
GPU-Virt-Bench streamlines the evaluation of GPU virtualization frameworks by running uniform tests across your hardware, models, and workloads. Instead of guessing which framework will perform best, it provides data-driven comparisons that expose trade-offs, bottlenecks, and real-world behavior under load.
- Structured performance tests — Runs a wide range of workloads—from tiny CUDA kernels to full LLM inference—and records how fast, slow, or stable the GPU behaves under each condition.
- Virtualization system comparison — Evaluates multiple options side-by-side, including native GPU performance (baseline), HAMi-core, BUD-FCSP, and other vGPU setups, revealing exactly how much overhead each one introduces.
- Isolation and fairness checks — Tests whether each tenant’s GPU slice is truly protected: Do other tenants cause slowdowns? Do usage spikes bleed across boundaries? Is memory or compute interference happening?
- LLM-relevant performance measurements — Focuses on what matters for modern AI workloads, including token generation speed, attention kernel throughput, KV-cache behavior, and multi-stream or multi-model concurrency—providing insights grounded in real AI deployment needs, not just synthetic metrics.
- Structured, comparable reports — Produces clean, machine-readable output (JSON, tables) so engineers can easily compare frameworks, spot regressions, and design better allocation or scheduling policies.
Categories & Evaluations
GPU-Virt-Bench organizes all of its tests into clearly defined categories so that performance and isolation can be evaluated in a structured, apples-to-apples way. Instead of running random isolated tests, the suite groups related measurements into these categories, and each category contains multiple metrics. This makes it easy to compare virtualization systems across specific dimensions such as overhead, fairness, LLM behavior, or memory performance. The categories include;
- Overhead Metrics : Measures the extra latency or slowdown introduced by virtualization.
- Isolation / Noisy-Neighbour Metrics: Tests whether one tenant can negatively impact another.
- LLM-Specific Performance Metrics : Focuses on token latency, attention throughput, KV-cache performance, etc.
- Memory & Bandwidth Metrics : Evaluates memory read/write speed, GPU memory fragmentation, allocator behavior.
- Cache Behavior Metrics : Measures how virtualization affects L2/L1 cache usage and eviction.
- PCIe / Interconnect Metrics : Benchmarks PCIe bandwidth, host-device transfer overhead, NUMA effects.
- NCCL / Multi-GPU Scaling Metrics : Checks how virtualization affects distributed training or inference throughput.
- Scheduling & Fairness Metrics : Evaluates how GPU time slices and scheduling decisions impact jitter or latency.
- Fragmentation & Resource Utilization : Shows how well memory and compute are partitioned between tenants.
- Error Recovery / Stability Metrics : Tests robustness under faults, OOM events, or heavy concurrency.
Use cases
GPU-Virt-Bench is designed to provide clear, actionable data about how virtualization behaves under real workloads. Here’s a few examples for how different teams can put it to work.
1. Infra / Virtualization Engineering
- Compare implementations — Run the same hardware and workloads across native GPU, HAMi-core, and BUD-FCSP, then use the JSON outputs and the –compare mode to see exactly where FCSP outperforms, matches, or falls behind HAMi-core.
- Tune your design — Overhead metrics such as OH-005 API interception, OH-007 memory tracking, and OH-008 rate-limiter overhead highlight which subsystems are adding latency, letting engineers prioritize the most impactful optimizations.
2. LLM Platform / Serving Team
- SLA & SLO design — LLM-focused metrics—like LLM-001 attention throughput, LLM-004 token generation latency, LLM-006 multi-stream performance, and LLM-010 multi-GPU scaling—show the real performance envelope you can guarantee when models run under virtualized GPUs.
- Dynamic batching & KV-cache strategy testing — By measuring KV-cache allocation speed and the effect of batching under virtualization, teams can validate whether their allocators or schedulers degrade when GPU slices are shared.
3. Cloud / Cluster Operators
- Noisy-neighbor and fairness validation — Isolation and bandwidth metrics (e.g., IS-009 noisy-neighbor impact, BW-001/BW-004, CACHE-002/003) reveal how well your stack isolates tenants and whether performance leaks across boundaries.
- Over-subscription policy design — Adjusting –processes, –memory-limit, and –compute-limit allows operators to safely explore how far they can over-subscribe GPUs, then convert the findings into robust scheduling policies.
4. Research & Product Advocacy
- Publishable evaluation methodology — With metrics grouped into 10 structured categories, researchers can directly export tables and figures into papers, blog posts, and whitepapers comparing BUD-FCSP, HAMi-core, or proprietary alternatives.
- Vendor-neutral, reproducible validation for customers — The framework provides defensible evidence when talking to customers or policymakers: you can say, for example, “On ERR-xxx and IS-xxx metrics our vGPU matches MIG-like behavior while preserving X% more flexibility,” backed by reproducible data.
5. Regression Testing & CI
- Continuous benchmarking — Integrate GPU-Virt-Bench into CI pipelines to run a selected metric set (key OH, IS, and LLM metrics) on every change to your virtualization stack, catching regressions long before they land in production.
These examples show how GPU-Virt-Bench becomes not just a benchmarking tool, but a shared performance truth across the organization—informing architecture, scheduling policy, research claims, and day-to-day engineering.
Frequently Asked Questions
1. What problems does GPU-Virt-Bench solve compared to traditional GPU benchmarking tools?
Traditional GPU benchmarks measure pure compute or memory performance, but they don’t reveal how GPUs behave when shared across multiple tenants. GPU-Virt-Bench solves this by:
- Testing virtualized GPU environments, not just native performance.
- Measuring isolation, fairness, noisy-neighbour effects, and virtualization overhead.
- Including LLM-specific metrics that reflect modern AI workloads.
- Providing structured, comparable output across different vGPU systems.
It gives developers a realistic view of how GPU sharing impacts workloads—something existing tools do not.
2. How do I compare multiple virtualization systems side-by-side using this framework?
You run GPU-Virt-Bench on the same hardware with different backends:
./gpu-virt-bench –system native
./gpu-virt-bench –system hami
./gpu-virt-bench –system fcsp
Then use its built-in comparison mode (e.g., –compare) or diff the generated JSON files to see Overhead differences, Isolation behavior, LLM performance, Memory, bandwidth, scheduling metrics. This gives a clean, apples-to-apples comparison.
3. What specific metrics or categories should I focus on if my main workload is LLM inference?
Key LLM-focused categories include:
- LLM Performance Metrics
(token latency, attention throughput, multi-stream concurrency) - Memory & Bandwidth Metrics
(KV-cache behavior, memory allocator impact) - Isolation Metrics
(noisy-neighbour effects on generation latency) - Scheduling Metrics
(latency jitter under contention)
These categories directly affect model throughput, latency, batching strategies, and multi-tenant behavior.
4. Can GPU-Virt-Bench simulate noisy-neighbour scenarios, and how configurable is the level of contention?
Yes. GPU-Virt-Bench includes isolation tests that run simultaneous workloads on different tenants. Developers can configure: Number of tenants/processes, Memory limits, Compute limits, Workload intensity and Types of interfering jobs (compute-heavy, memory-heavy, etc.) This lets you model anything from mild contention to fully hostile neighbours.
5. How does the tool measure and validate isolation between tenants?
It measures isolation by running two or more workloads simultaneously, stressing specific GPU subsystems (compute, memory, cache, PCIe), Recording whether one workload slows down, jitters, or loses bandwidth and Checking for interference in metrics such as Latency changes, Bandwidth drops, Cache eviction patterns, Scheduling fairness. Isolation metrics quantify exactly how much one tenant affects another.
6. What types of workloads and models are supported out-of-the-box, and can I add custom workloads?
Out of the box, GPU-Virt-Bench includes CUDA microbenchmarks, Bandwidth and memory tests, Cache and PCIe tests, LLM-specific workloads (token generation, attention kernels, etc.)
Custom workloads: Yes, you can add them, as the framework is designed to be extensible. Developers can integrate, custom CUDA kernels, Their own inference workloads and proprietary model tests. This makes it useful across different ML stacks.
7. How should I interpret the JSON output, and is there support for automated regression testing in CI pipelines?
JSON reports contain: Raw metrics, Category groupings, Per-system comparisons, Timestamped runs. These can be: Parsed with Python, Visualized in dashboards or Stored as baselines for regression detection.
CI Integration: Yes. GPU-Virt-Bench is CI-friendly. You can run it with a minimal test set (e.g., key overhead, isolation, and LLM metrics). CI pipelines can diff JSON outputs to detect regressions in virtualization behavior. This ensures stability across code updates.
8. How accurate are the LLM-specific metrics, and do they reflect real-world deployment behavior under virtualization?
Yes—by design, the LLM metrics aim to reflect real inference behavior, because they measure Token latency, Attention throughput, KV-cache performance, Multi-model concurrency, Multi-GPU scaling. These are the exact bottlenecks seen in real systems using LLMs under contention. That said, the absolute accuracy depends on Model implementation, Tokenizer/runtime, Hardware backend, Virtualization system details.







.png)