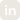Ensuring that language models behave safely, ethically, and within intended boundaries is one of the most pressing challenges in AI today. That’s why we’re excited to share the release of the largest open dataset ever published for AI guardrails: budecosystem/guardrail-training-data.
Why Guardrails Matter
The rise of language models has unlocked extraordinary possibilities: they can write with fluency, solve complex problems, and assist with everything from coding to creative storytelling. Yet, behind this potential lies a fragile balance. Without safeguards, these systems can be pushed off course—exploited, manipulated, or led into producing harmful and unsafe outputs. They are susceptible to:
- Jailbreaks and prompt injections: Users can sometimes trick a model into bypassing its built-in safety rules, leading it to generate instructions for harmful or unethical activities.
- Toxic or harmful outputs: Without guardrails, models can produce hate speech, offensive language, or content that incites violence.
- Misinformation and deception: Models can produce false or misleading information that looks credible.
- Sensitive or dangerous guidance: From self-harm encouragement to privacy violations or cyberattack instructions, unfiltered outputs can cross into high-risk territory.
- Bias and discrimination: Trained on large swaths of internet data, models may unintentionally reproduce stereotypes or unfair judgments.
These vulnerabilities are not edge cases—they are structural risks inherent to large-scale generative AI. And that’s why robust guardrails are essential: to make sure AI systems are not just intelligent, but also responsible and trustworthy.
The urgency of strong AI guardrails isn’t hypothetical—it’s real. Just last week, The Guardian reported on a tragic case where ChatGPT was linked to a user’s suicide, raising questions about accountability and the limits of current safety measures. Incidents like this are sobering reminders that the risks of unguarded AI go beyond offensive language or misinformation—they can touch the most vulnerable parts of human life.
Guardrails—systems that detect and filter harmful or unsafe content—are essential to making AI deployment safe, reliable, and aligned with human values. The challenge is that building robust guardrails requires high-quality, large-scale data across diverse harm categories.
Our Dataset at a Glance
When we set out to build the Bud AI Foundry, one of our top priorities was clear: create the strongest guardrail system possible. Guardrails aren’t an afterthought—they are the foundation of safe and responsible AI.
To achieve that, we curated and trained on a dataset of about 4.5 million labeled samples—the largest collection ever assembled for guardrail systems. This scale gives us the diversity and depth needed to handle the wide spectrum of risks that modern AI faces, from jailbreak attempts to misinformation, hate speech, and beyond.
Now, we’re taking the next step: open-sourcing the dataset. We believe that safety in AI should not be a competitive advantage locked inside one company—it should be a shared resource. By releasing this dataset under an open license, we’re empowering researchers, startups, and enterprises everywhere to build, test, and improve their own guardrails. Because when it comes to AI safety, collaboration is the only way forward.
Key stats:

- Size: 4,495,893 samples
- Tasks: Text classification and text generation
- Processing time: 96.5 seconds
- Language: English
- License: Apache-2.0 (open for research and commercial use)
Coverage Across 26 Harm Categories
Unlike smaller moderation datasets, this release is designed to be comprehensive and fine-grained, spanning 26 categories. The table below shows the key categories, total samples in each category and category size.
The dataset includes the following harm categories
- jailbreak_prompt_injection
- violence_aiding_and_abetting_incitement
- hate_speech_offensive_language
- self_harm
- discrimination_stereotype_injustice
- sexually_explicit_adult_content
- financial_crime_property_crime_theft
- malware_hacking_cyberattack
- privacy_violation
- fraud_deception_misinformation
- drug_abuse_weapons_banned_substance
- child_abuse
- animal_abuse
- terrorism_organized_crime
- non_violent_unethical_behavior
- code_vulnerabilities
- misinformation_regarding_ethics_laws_and_safety
- And more…
This granularity allows developers to build multi-class moderation systems or tailored safety filters that align with specific organizational needs.
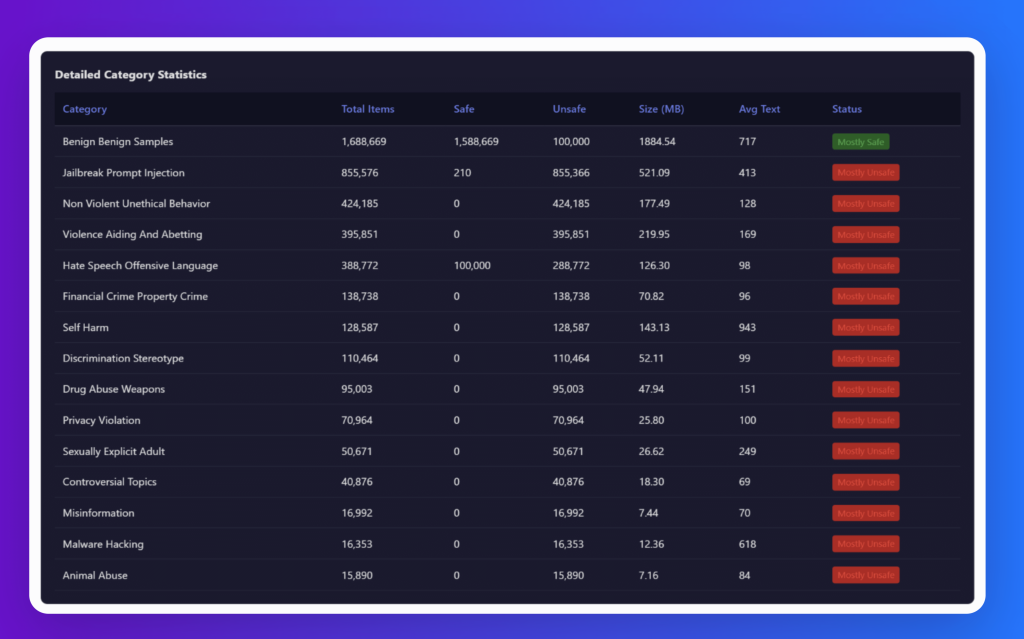
The chart below shows the dataset size distribution across harm categories, highlighting that benign content makes up the largest share (nearly 2GB), followed by jailbreak prompts, while other categories like violence, hate speech, self-harm, and privacy violations are smaller but still represented—illustrating both the scale and diversity of the dataset.
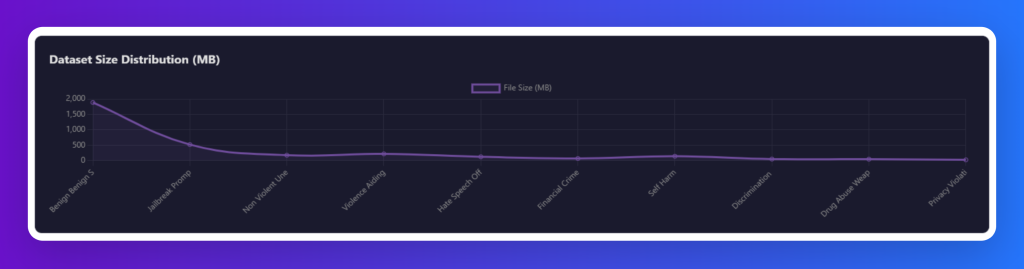
Distribution of samples
The chart below reveals how the dataset is structured around different types of harmful content. The largest share comes from violence-related content, followed by non-violent unethical behavior and hate speech, showing clear emphasis on the most pressing risks. Mid-sized portions include financial crime and discrimination, while smaller but essential categories like drugs/weapons, self-harm, and privacy violations ensure broader coverage. Together, this distribution shows that the dataset isn’t just massive in scale—it’s carefully balanced to capture both the most frequent harms and the most critical edge cases.
Risk Severity Distribution
The dataset is intentionally weighted toward high-severity risks, ensuring that guardrail systems are stress-tested against the most urgent and potentially harmful threats, while still maintaining representation of lower and critical risks for full-spectrum coverage.
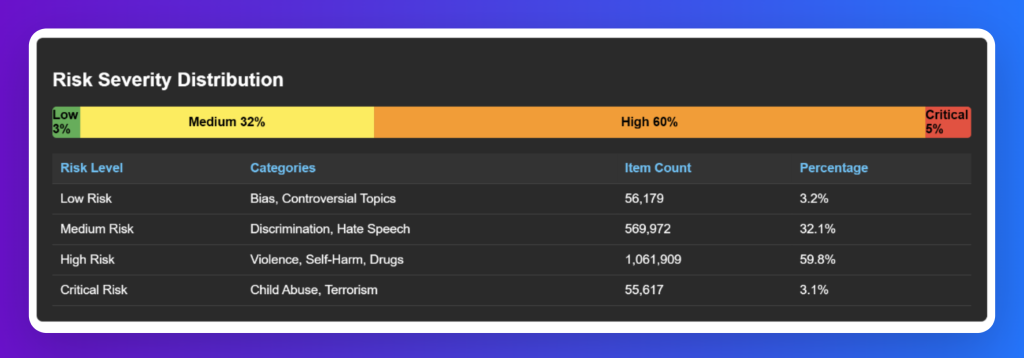
The dataset is heavily weighted toward high-risk content (60%), such as violence, self-harm, and drugs, ensuring strong guardrail coverage against the most dangerous threats. Medium-risk categories like discrimination and hate speech make up 32%, reflecting their frequency and social impact. Critical risks—child abuse and terrorism—account for 5%, representing the most severe harms, while low-risk content such as bias and controversial topics contributes just 3%, adding nuance without dominating the dataset.
Category Co-occurrence Matrix
Harmful categories rarely exist in isolation. The dataset reflects how risks like violence, hate, and discrimination intertwine, which is critical for building guardrails that can detect complex, overlapping harms rather than treating each risk in isolation.
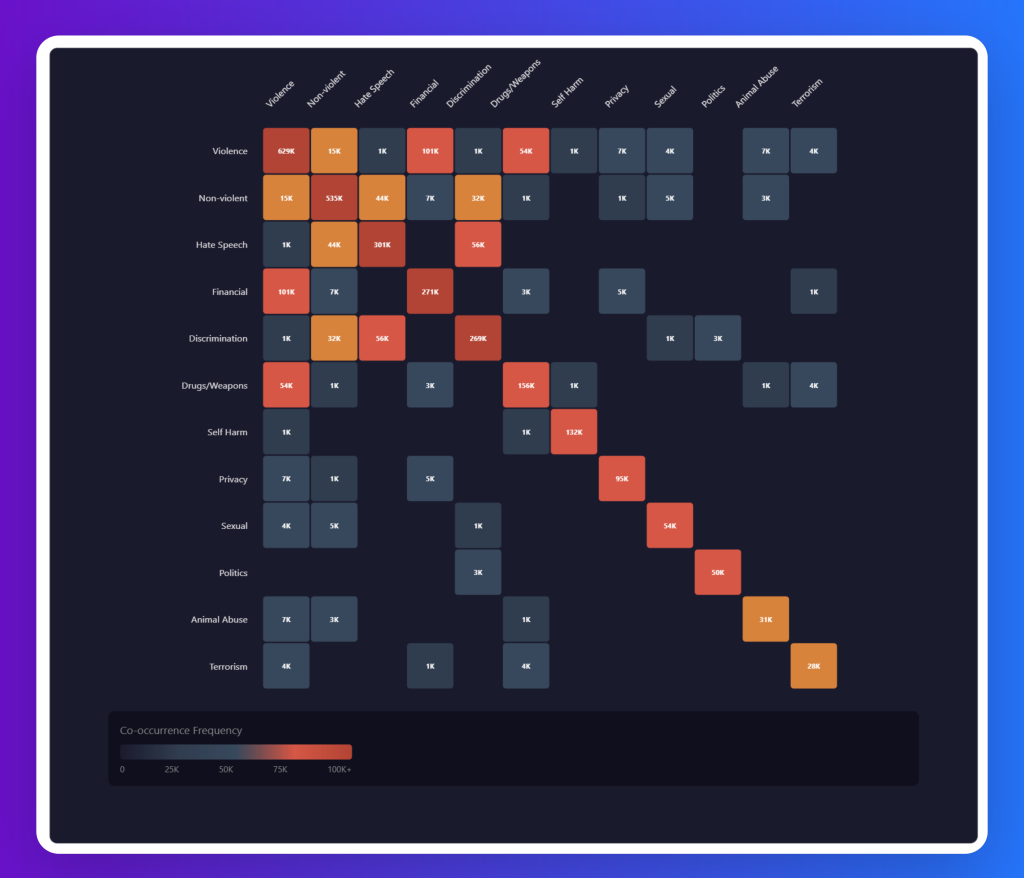
This chart highlights how harmful categories often overlap within the dataset, underscoring the multi-dimensional nature of AI risks. Violence shows the strongest co-occurrence, frequently intersecting with hate speech (44K), financial crime (101K), and self-harm (54K), while non-violent unethical behavior overlaps with discrimination (32K) and hate speech (33K). Hate speech and discrimination are closely linked (54K), and self-harm often appears alongside sexual content (99K) and drugs/weapons (132K). Even smaller categories like animal abuse and terrorism connect with violence, politics, and sexual content, illustrating that harmful content rarely exists in isolation and requires guardrails capable of detecting complex, overlapping threats.
Applications and Impact
This dataset opens up new possibilities for the AI community by serving as both a training ground and a benchmark for safety. With nearly 4.5 million labeled examples across dozens of harm categories, it enables developers to train far more robust safety classifiers—models capable of catching subtle risks and recognizing a much wider spectrum of harmful behaviors than ever before.
It also provides the opportunity to test guardrails under truly adversarial conditions, including jailbreaks and prompt injections that are specifically designed to bypass protections. By stress-testing systems against these edge cases, teams can identify weaknesses early and build guardrails that stand up to real-world challenges.
Beyond practical deployment, the dataset contributes to the broader field of research by offering a shared benchmark for AI safety and content moderation. Instead of working in silos, researchers and practitioners can evaluate their methods against the same large-scale, open dataset—helping the community move faster, compare results more fairly, and push the boundaries of what responsible AI can achieve.
Usage
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
from datasets import load_dataset # Load the full dataset dataset = load_dataset("BudEcosystem/guardrail-training-data") # Access different splits train_data = dataset['train'] val_data = dataset['validation'] test_data = dataset['test'] # Filter by safety status harmful_samples = dataset['train'].filter(lambda x: not x['is_safe']) safe_samples = dataset['train'].filter(lambda x: x['is_safe']) # Filter by specific category jailbreak_samples = dataset['train'].filter(lambda x: 'jailbreak' in x['category']) # Parse metadata for additional fields import json for sample in dataset['train'].select(range(5)): metadata = json.loads(sample['metadata']) print(f"Text: {sample['text'][:100]}...") print(f"Category: {sample['category']}") print(f"Metadata fields: {list(metadata.keys())}") |
Looking Ahead
This dataset is just the beginning. We believe that open, large-scale resources are critical for building safe, trustworthy AI. By making this dataset freely available, we invite researchers, developers, and organizations to collaborate in advancing AI safety at scale. Together, we can make sure that the next generation of AI systems isn’t just powerful—but also safe, aligned, and worthy of trust.
👉 Explore the dataset here: budecosystem/guardrail-training-data







.png)