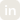We have a major upgrade to our LLM Evaluation Framework — making it even more powerful, transparent, and scalable for enterprise AI workflows. As the adoption of LLMs accelerates, evaluating their performance rigorously and reliably across real-world tasks has never been more critical. Our new framework brings unprecedented flexibility and depth to benchmarking LLMs at scale.
What’s New in the Framework?
Our upgraded LLM Evaluation Framework delivers four major enhancements designed to streamline evaluation and empower AI teams:
100+ Datasets, Instantly Available
Quickly assess model capabilities using a comprehensive suite of over 100 pre-integrated evaluation datasets. These span academic benchmarks, open-domain tasks, and industry-specific evaluations, enabling wide-ranging, diverse model assessments.
Real, Reproducible Metrics for Comparability
Benchmarks now generate transparent, quantitative scores that can be directly compared across models. Whether you’re testing GPT-4, Claude, or custom fine-tuned models, you get consistent, reproducible metrics that ensure evaluations are both fair and auditable.
Customizable Benchmarks for Unique Use Cases
Every enterprise has unique requirements. The framework allows deep customization of evaluation tasks — from dataset selection to scoring logic and prompt style — so teams can tailor benchmarks to align with domain-specific needs or compliance criteria.
Effortless Scaling with Distributed Evaluation
Evaluate thousands of samples in parallel using our built-in support for distributed compute. Whether you’re running evaluations on a local cluster or the cloud, the framework adapts seamlessly to your infrastructure and scaling needs.
Deep Evaluation Across 8 Fundamental Dimensions
The framework now benchmarks models across eight core cognitive competencies, offering holistic insights into model performance:
- Language Comprehension
- Knowledge Precision
- Logical Deduction
- Creative Ideation
- Mathematical Problem-Solving
- Programming Proficiency
- Extended Text Analysis
- Intelligent Agent Engagement
These dimensions map to real-world applications and research challenges, allowing teams to evaluate where a model excels — and where it may fall short — in capabilities that matter.
Supported Tasks: Real-World, Multidisciplinary, Multilingual
Our evaluation suite includes coverage for a wide range of tasks:
- NLP Tasks: Sentiment Analysis, Intention Recognition, Summarization, Translation, Information Retrieval, Multi-turn Conversations
- Knowledge & Reasoning: Common Sense Reasoning, Natural/Social/Humanity Sciences, Logical & Deductive Reasoning, Cultural Understanding
- Math & Programming: Primary to High-School Math, Code Generation, Code Understanding, Reasoning
- Advanced Use Cases: Function Calling, Reflection, Planning, Long-context Creation, Rephrasing, Expansion & Continuation
This diversity ensures LLMs are tested not only on surface-level fluency but also on their deeper cognitive and technical abilities. It also supports zero-shot, few-shot and chain-of-thought evaluations. Whether you’re comparing raw LLMs or fine-tuned systems with specialized prompting, our framework gives you the flexibility to measure what’s relevant.
What This Means for Enterprises
For organizations, these upgrades provide a robust and trustworthy way to evaluate AI models. They enable faster innovation by allowing teams to quickly compare and select the right models for their workflows. By basing decisions on real-world, reproducible performance, organizations can reduce risk and make smarter AI investments that align with their unique goals and constraints. The framework is compliance-ready, offering transparent metrics that satisfy both regulatory requirements and internal auditing standards. Designed to scale, it integrates seamlessly into existing AI pipelines and grows with your model fleet. Whether you’re developing agents, deploying chatbots, or automating document processing, this framework empowers your team with the clarity and confidence to move fast—without breaking things.




.png)