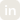
Building an AI agent has never been easier. With today’s models, a developer can wire up a prompt, attach a tool or two, give it a goal, and have something that behaves like an intelligent agent working in an afternoon. The demo is impressive. The notebook runs. Everyone in the room nods.
Then it goes to production, and that’s where the story usually falls apart.
Because the moment an agent leaves the laptop and enters a real enterprise environment, an entirely different class of problem appears, and none of it has anything to do with prompts.
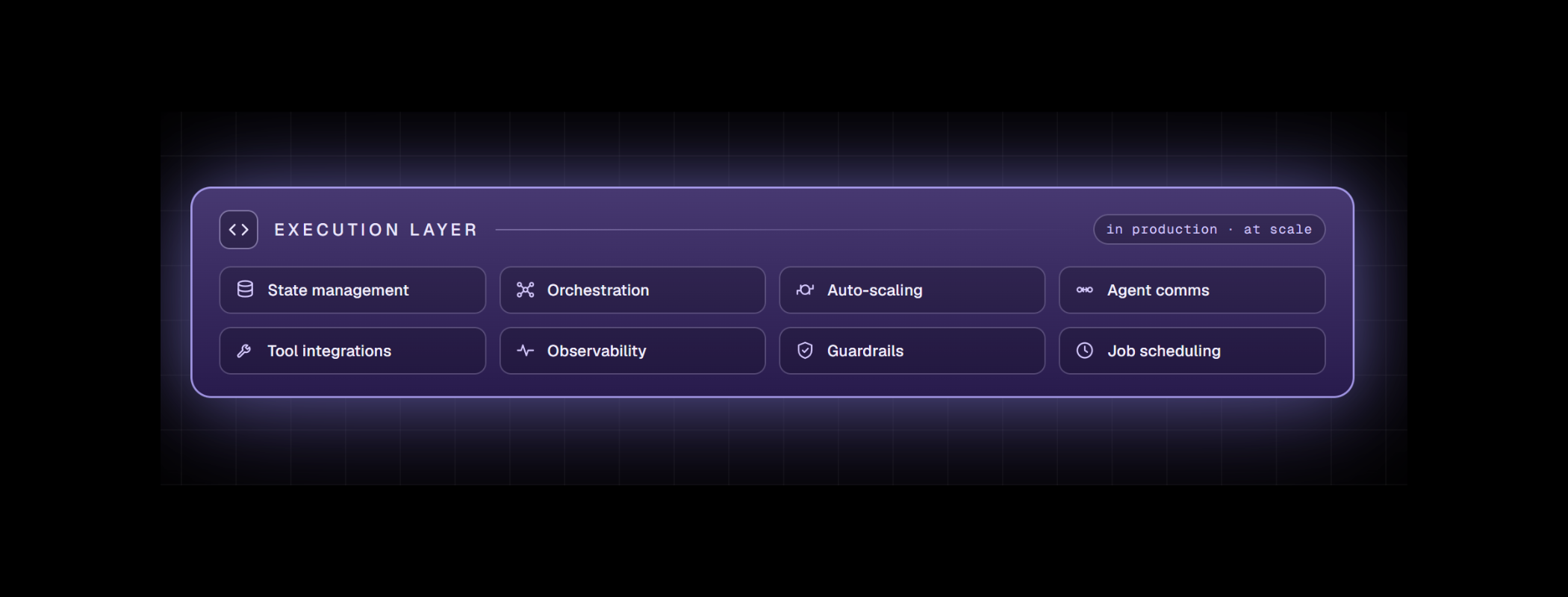
- How do you handle thousands of simultaneous agent requests without your infrastructure buckling?
- What happens when a tool call fails halfway through a ten-step workflow that has already consumed real time and real tokens?
- How do you maintain context not just across steps, but across sessions, and across server restarts?
- How do you give each agent a verifiable identity?
- How do you scale a fleet of agents up and down without either melting your budget or losing their state?
- How do you recover cleanly when a node dies mid-task?
- And once you have hundreds of agents loose in production, how do you actually see what any of them are doing?
That list does not end. Identity, scaling, recovery, observability, orchestration, security, scheduling: every one of them is a hard distributed-systems problem in its own right. Solving all of them by hand, for every agent your teams build, would be a nightmare. It is also completely unrelated to the thing your teams are actually good at, which is designing intelligent agents.
This is the gap Bud Agent Runtime exists to close.
What Bud Agent Runtime Is
Bud Agent Runtime is the execution layer that sits between your agent logic and the underlying infrastructure.
Your agent logic handles the interesting part: prompts, reasoning, decisions, and which tools to call when. The infrastructure underneath handles raw compute, networking, and storage.
Bud Agent Runtime is the layer in the middle that makes the two work together reliably, at scale, in production. It absorbs state management, orchestration, auto-scaling, communication between agents, tool integrations, observability, guardrails, and job scheduling, so that the teams building agents never have to think about any of it.
You define the behavior. The runtime handles everything underneath. That separation is the entire point: it is what lets a developer stay focused on building an intelligent agent without simultaneously having to become a distributed-systems engineer.
Think of It in Three Layers
The cleanest way to understand the runtime is as the middle tier of a three-layer stack.
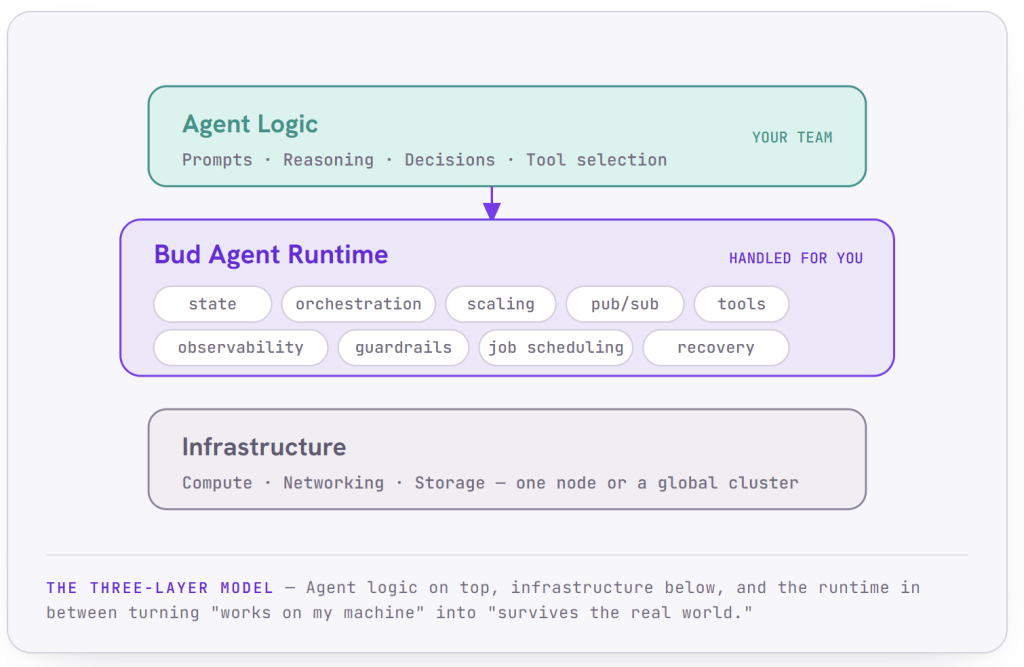
At the top sits your agent logic: the prompts, the reasoning, the decisions about which tools to call and when. This is what your team writes and iterates on.
At the bottom sits the infrastructure: compute, networking, and storage, whether that is a single node or a sprawling multi-region cluster.
In between sits Bud Agent Runtime, handling execution, scaling, state, communication, security, and recovery. It is the layer that turns “agent code that works on my machine” into “agentic system that survives contact with the real world.”
Everything that follows in this article is a description of what that middle layer actually does, and why each piece matters when the stakes are real.
The Principles Behind the Design
Before getting into individual capabilities, it helps to understand the design philosophy, because the capabilities follow from it.
Backed by Durable Workflows
Durability is not an add-on; it is the foundation. Agents are backed by a durable workflow engine, which means every LLM call and every tool execution is durable, auditable, and resumable. Workflow checkpointing guarantees that an agent can recover from a failure at any point while keeping its state consistent. The same workflow foundation also provides centralized, deterministic control over how multiple agents coordinate, so complex multi-agent processes stay reliable without sacrificing the autonomy of the individual agents. The result is a system that combines the predictability of deterministic execution with the intelligence of LLM-powered reasoning.
Modular and Pluggable
The runtime is built on a pluggable component model. Capabilities like messaging, state, and secrets are defined as building blocks, and each building block runs on interchangeable backends. You can swap the underlying state store from one technology to another, or change message brokers, or move from one LLM provider to another, without rewriting your agent code. The practical payoff is enormous: teams develop locally with simple default configurations, then deploy to a demanding cloud or on-premise environment by changing configuration, not code.
Message-Driven
Communication between agents is event-driven, built on publish/subscribe messaging. This keeps the architecture loosely coupled and asynchronous, which is what allows it to scale and to adapt in real time. Agents react dynamically to events rather than being hard-wired to one another, and pub/sub combined with workflows lets agents both collaborate autonomously through event streams and participate in structured, orchestrated processes.
Decoupled from Infrastructure
There is a clean separation between agents and the infrastructure beneath them. Agents focus purely on reasoning and task execution; routing, validation, messaging, and the rest are handled externally by modular infrastructure components. Offloading everything that isn’t agent-specific is what lets agents scale independently and adapt to new use cases and integrations without being rewritten.
What’s Under the Hood
When you zoom into the runtime layer, you find a set of battle-tested building blocks working together. These are the primitives that turn an agent from a script into a distributed, reliable service.
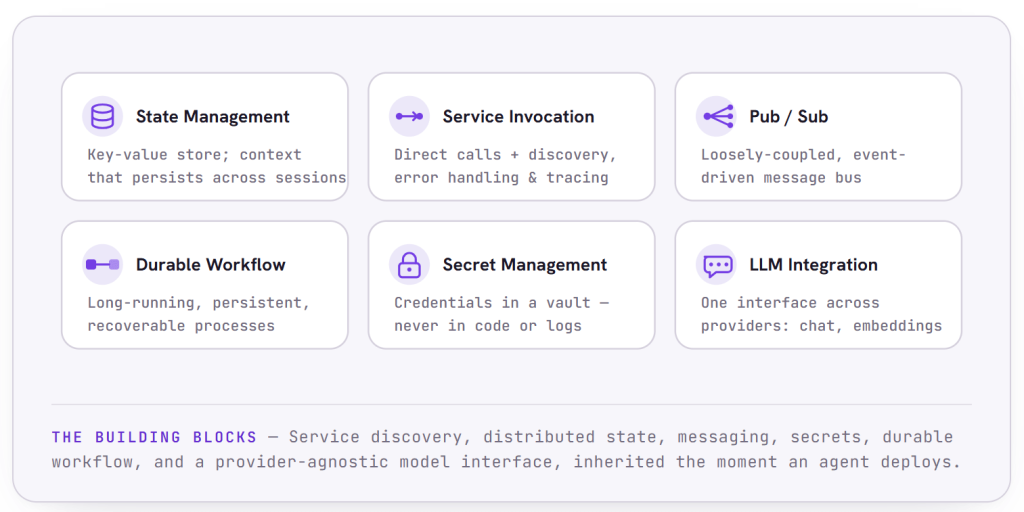
State management gives every agent a flexible key-value store to retain context across interactions, so continuity and memory persist across steps and sessions rather than living only in volatile memory.
Service-to-service invocation lets agents call one another directly, with built-in service discovery, error handling, and distributed tracing baked in. This is the synchronous backbone for multi-agent workflows: one agent can reliably reach another without anyone hand-rolling networking code.
Publish/subscribe messaging provides the asynchronous, loosely coupled backbone. Agents collaborate through a shared message bus, enabling real-time, event-driven task distribution and coordination without tight dependencies.
Durable workflow defines long-running, persistent processes that blend deterministic steps with LLM-based decision-making. This is what orchestrates complex, multi-step agentic work and keeps it recoverable.
Secret management keeps credentials, API keys, and tokens out of code, logs, and prompts, storing them in a vault and exposing them only by secure reference.
LLM integration abstracts the inference layer, so chat completion, embeddings, and other model interactions are handled through a consistent interface regardless of which provider sits behind it.
Because all of these are provided as proven primitives rather than things each team rebuilds, an agent inherits service discovery, distributed state, messaging, secrets, and tracing the moment it is deployed.
Durable Execution: Built for Survival
Real-world agentic operations are unpredictable. Processes crash. Nodes restart. Networks drop. In most systems, any one of those events means a workflow collapses and starts over from the beginning, which for a long-running, multi-step agent can mean lost work, wasted tokens, and a user left staring at a spinner.
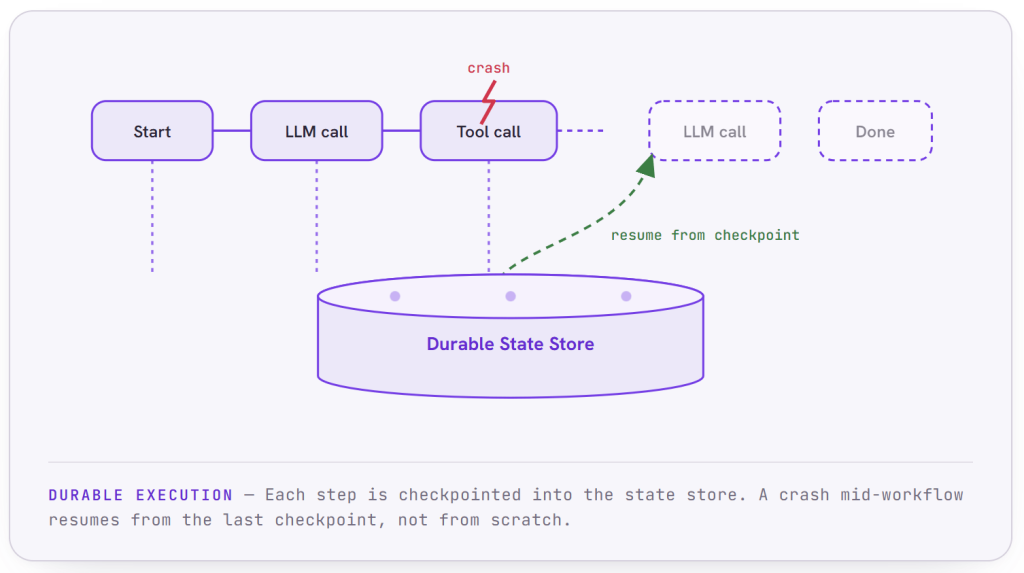
Bud Agent Runtime is built so that workflows do not collapse every time the infrastructure does.
The mechanism is durable execution. Every LLM call and every tool execution is persisted into a durable state store as it happens, so the runtime is continuously checkpointing the agent’s progress. When something goes wrong, the agent does not restart from scratch. It recovers from its last good checkpoint and continues exactly where it left off, with its state intact, as if the interruption never happened. Tasks are automatically distributed across the cluster, and if one fails it is retried and recovers its state from the point of failure. Developers do not need to understand any of the workflow-engine internals to get this; they write an agent that performs tasks, and durability comes for free.
And this is far more than naive retry logic. The runtime applies a two-tier resilience strategy. For transient failures, a momentary timeout or a brief service hiccup, it uses automatic retry policies, configurable timeouts, and circuit breakers that stop a struggling dependency from dragging the whole system down. For longer outages, it falls back on durable retries backed by persistent workflow state, so a process interrupted for minutes or longer can still resume cleanly once the underlying problem clears.
The practical effect is that “the server restarted mid-workflow” stops being a catastrophe and becomes a non-event.
Scale and Performance Without the Overhead
Scaling agentic systems is supposed to require a small army of servers and a correspondingly large bill. Bud Agent Runtime breaks that assumption with a virtual actor model.
In this model, every agent is treated as a lightweight, thread-safe, natively distributed unit of compute and state, not a heavyweight process that hogs resources simply by existing. Because each agent is so light, thousands of them can run concurrently, on demand, on a single core, with latency in the low double-digit milliseconds even when scaling up from nothing. You get massive concurrency without massive infrastructure.
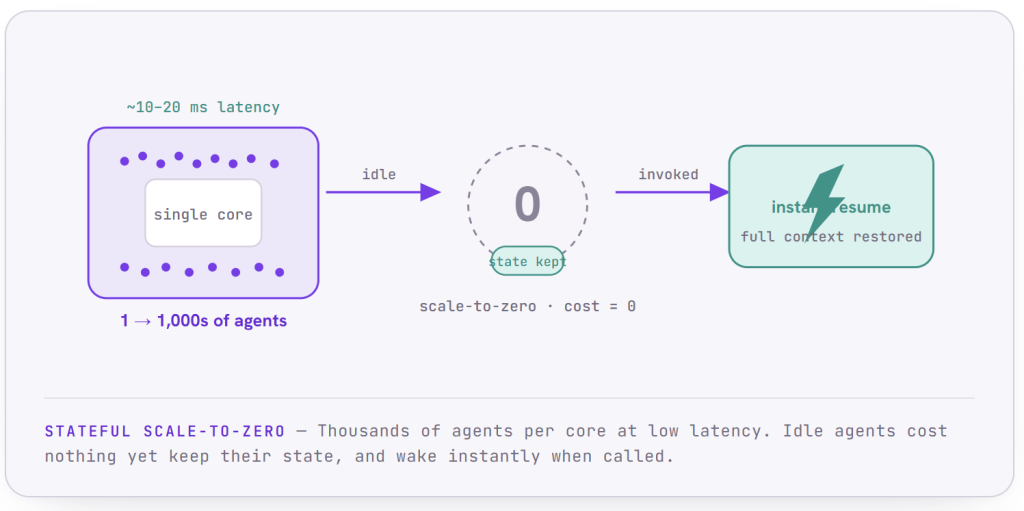
The other half of the equation is what happens when agents are idle, which is most of the time for most agents. The runtime uses stateful scale-to-zero. When an agent goes idle, the system reclaims its compute entirely, scaling it down to nothing, while preserving its state. The instant that agent is invoked again, it re-illuminates with its full context restored. You are never paying to keep thousands of idle agents warm, and you are never losing their state to save money.
This is what makes serious AI adoption cost-effective for organizations of every size. The usual trade-off between performance and resource efficiency simply goes away: you get both, because the architecture was designed so you don’t have to choose.
Security Built In, Not Bolted On
An agentic system cannot operate on blind trust. As agents gain access to enterprise data, internal tools, and sensitive workflows, security has to be a property of the runtime itself, enforced by the platform, not a feature someone remembers to add later. Bud Agent Runtime embeds security at every layer.
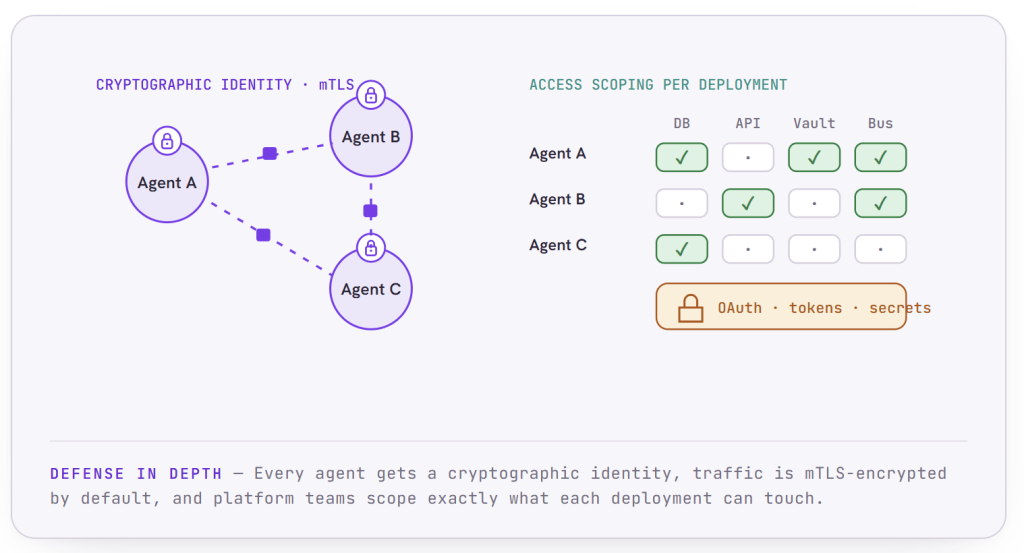
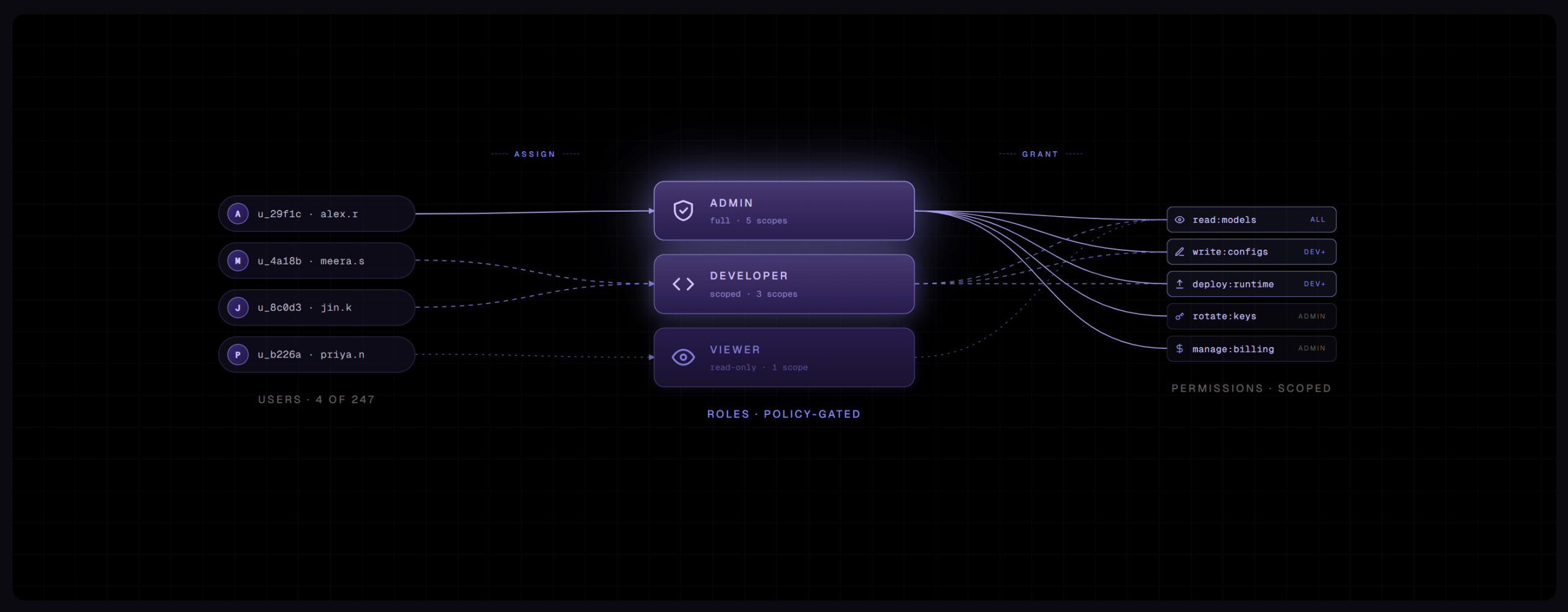
Every agent receives a unique cryptographic identity. That identity is the basis for everything else: agents can prove who they are, and the system can verify it. All communication between agents is encrypted by default using mutual TLS, so traffic between agents is authenticated and protected end to end without anyone configuring it specially.
On top of that, platform and infrastructure teams get fine-grained access control. They can scope exactly which data stores and which services each agent deployment is permitted to touch, an explicit allow-list rather than an implicit free-for-all. An agent built to summarize support tickets has no path to the financial database unless someone deliberately grants it. Those same teams can apply resiliency policies, timeouts, retries, and circuit breakers, to the very databases and message brokers the agents depend on, so reliability and security are governed in one place.
The runtime also handles credentials properly. With built-in OAuth, API token, and secrets management, agents authenticate to external services without credentials ever being exposed in code, logs, or prompts. Secrets live in a vault and are referenced, never embedded.
The net result is an agentic system you can actually put in front of an enterprise security review, because trust is enforced by the runtime rather than left to hope.
Full Observability, End to End
You cannot operate what you cannot see. Once you have agents making their own decisions and calling tools on their own, “it’s probably fine” is not an acceptable answer to “what is the system doing right now?”
Bud Agent Runtime gives you complete visibility into everything your agents do. Every tool call, every LLM interaction, every workflow step is traceable from start to finish. When you need to understand why an agent produced a particular result, or where a request slowed down, or which step failed, you can follow a single request as it moves across the spans of a trace, the same way you would debug any well-instrumented distributed system. Distributed tracing is built into the service-invocation layer, so this visibility is inherent rather than something you wire up afterward.
Because observability is built on open, standard tooling, it slots straight into the monitoring stack your organization already runs, surfacing traces, metrics, and logs through familiar dashboards. This is the difference between a system that’s debuggable and auditable and one that’s a black box. For agentic systems, where behavior is probabilistic and the stakes are real, end-to-end traceability is not a nice-to-have. It is the foundation of trust and the prerequisite for compliance.
Where It Gets Powerful: Multi-Agent Collaboration
A single capable agent is useful. A system of agents that can collaborate is transformative, and this is where the runtime’s architecture really earns its keep.
The foundation is event-driven. Agents communicate through publish/subscribe messaging, so they do not have to be hard-wired to one another. An agent publishes an event; other agents subscribe to what is relevant to them. This loose coupling is what lets a fleet of agents grow and rearrange itself without becoming a tangle of brittle point-to-point connections.
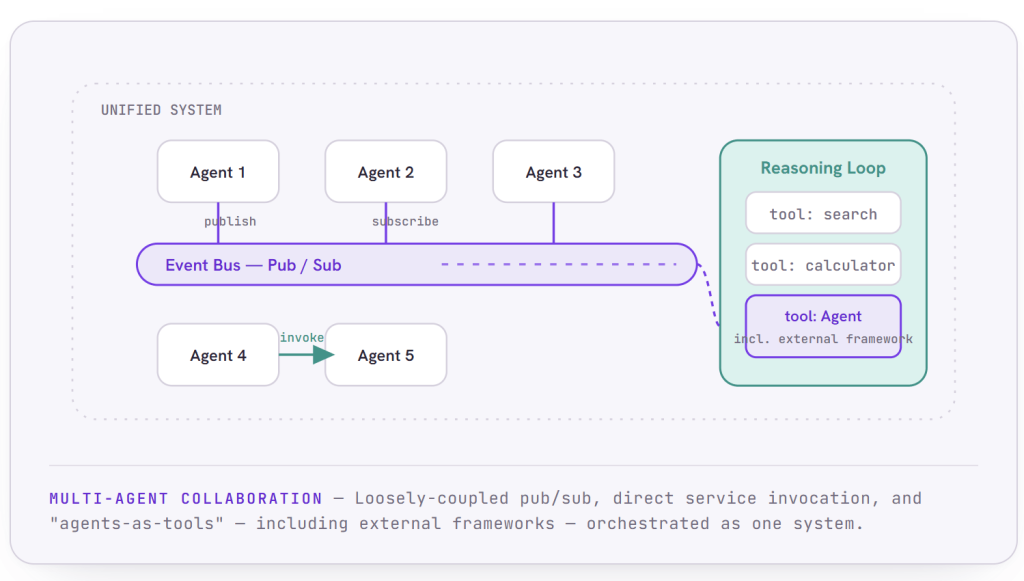
When tighter coordination is needed, agents can discover and directly invoke one another through service invocation, complete with discovery, error handling, and tracing. And most powerfully, an agent can use another agent as a tool inside its own reasoning loop, including agents built on external frameworks. From the calling agent’s perspective, another agent is just another capability it can reach for, the same way it reaches for a calculator or a search tool.
Put those pieces together and you can orchestrate genuinely complex multi-agent workflows that behave as a single, coherent, intelligent system, while underneath, the runtime quietly handles the discovery, the messaging, the coordination, and the recovery.
Data-Centric Agents
An agent that cannot reach your data is a chatbot. Real enterprise value comes from agents that operate on real information, structured and unstructured, sitting in dozens of different systems.
Bud Agent Runtime is built for this. It offers built-in connectivity to a wide range of enterprise data sources, handling everything from straightforward document and PDF extraction to large-scale database interactions. Through its bindings, its state stores, and its support for the Model Context Protocol, agents can ingest data from numerous sources with minimal code. That means a data-driven agent, one that reads from a warehouse, pulls context from documents, and writes results back to a system of record, can be built and changed quickly, without each integration becoming a bespoke engineering project.
This data-centricity is what moves agents from impressive demos to load-bearing parts of a business process.
A Complete Developer Surface
The runtime is not only about operational guarantees. It also gives developers a complete API surface for the problems that come up again and again when building agents, so they are not reinventing these wheels each time. That surface includes flexible prompting, structured outputs for when you need machine-readable results rather than free text, support for multiple LLM providers behind a consistent interface, contextual memory so agents remember across interactions, intelligent tool selection, native Model Context Protocol integration, and first-class multi-agent communication.
Taken together, these accelerate development dramatically. The hard, repetitive scaffolding is already built and hardened, so teams spend their time on the part that differentiates their product: the agent’s behavior and intelligence.
Portability and Freedom from Lock-In
Because the runtime is built on a modular, pluggable component model, the backends it runs on are interchangeable. The state store, the message broker, the secret store, and the model provider are all configuration choices, not architectural commitments. Develop against simple local defaults, then deploy to a hardened production environment, an on-premise cluster, a sovereign cloud, or a hybrid of all of them, by updating component definitions rather than rewriting application code.
This portability is not a minor convenience. It is what keeps an organization in control of its own AI stack, free to choose where workloads run and which technologies sit underneath, without being trapped by a single vendor’s proprietary platform. For enterprises that care about sovereignty, hardware-agnosticism, and the ability to audit and adapt what they run, that freedom is the whole game.
Seven Agentic Patterns, Out of the Box
You do not have to start from a blank canvas. Bud Agent Runtime ships with seven proven agentic design patterns, spanning the full spectrum from simple, predictable workflows to fully autonomous agents.
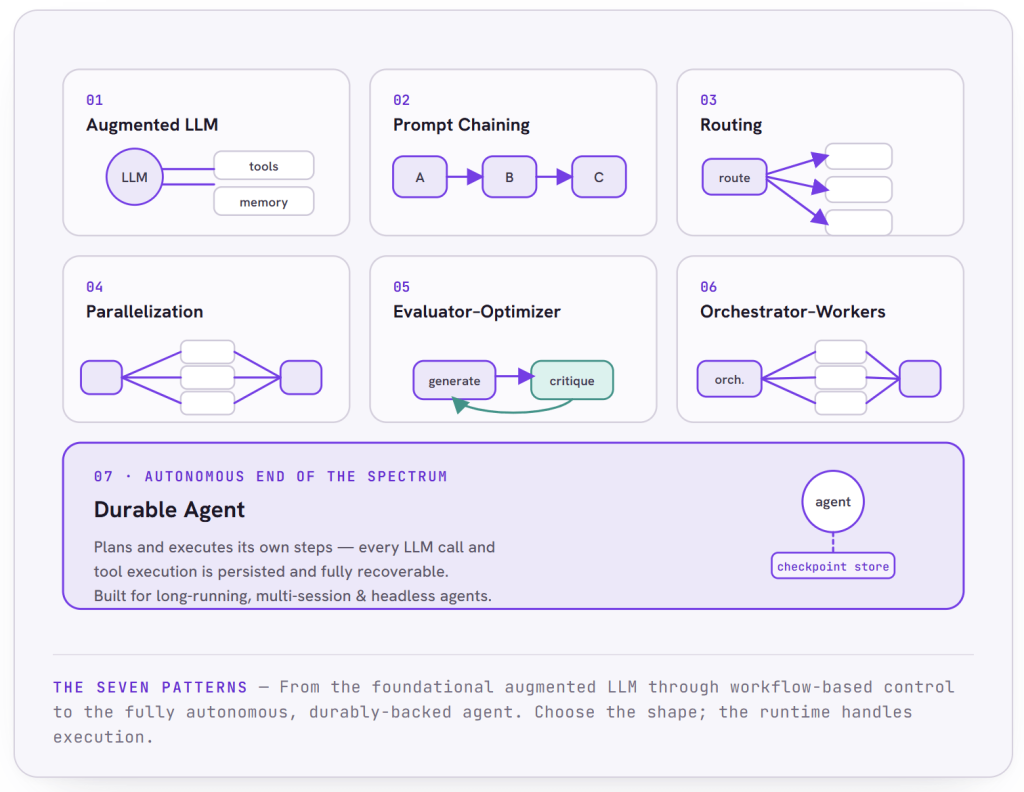
That spectrum matters. At one end are workflows, where models and tools are orchestrated through predefined code paths; these are prescriptive and offer predictability, consistency, and control. At the other end are autonomous agents, which direct their own strategies and tool usage; these offer flexibility and adaptability. Fully autonomous agents sound appealing, but for well-defined tasks, workflows often deliver the reliability and maintainability that enterprises actually need. Most real problems are best served somewhere along that spectrum, and the runtime supports the entire range. The patterns below progress roughly from the simplest building block toward greater autonomy.
Augmented LLM is the foundational building block: a language model enhanced with memory and tools. It is the right choice when you need a capable, context-aware assistant without complex orchestration, such as a support agent that can look up product information, or a research helper that remembers what you are working on. The runtime handles the configuration, the memory persistence, and the tool integration underneath.
Prompt Chaining decomposes a task into a sequence of steps, where each call processes the output of the previous one. It is ideal when you want control and validation between steps: generate an outline, expand it, then review it. It also lets you insert quality gates, stopping or redirecting the workflow if an intermediate result fails a check.
Routing classifies an incoming request and directs it to the right specialized handler. It is how you build a system that sends simple queries to a smaller, cheaper model and hard ones to a more capable model, routes different kinds of customer questions to different experts, or directs queries by language. Classification is LLM-powered, while the routing itself uses familiar, extensible control flow.
Parallelization processes multiple independent dimensions of a problem at the same time and then aggregates the results. When a task has subtasks that do not depend on one another, researching several aspects of a topic, drafting several sections of a document, running them concurrently is faster, and the runtime handles the orchestration, the synchronization, and the durability of the whole parallel process.
Orchestrator-Workers is for complex tasks where you cannot know the subtasks in advance. A central orchestrator dynamically breaks the work down, delegates pieces to worker agents, and synthesizes their outputs. Unlike the more predefined patterns, the orchestrator determines the workflow at runtime based on the specific input, which makes this the pattern for open-ended work such as multi-file software changes or research that spans many sources.
Evaluator-Optimizer runs a generate-and-critique loop: one model produces a result, another evaluates it against defined criteria and gives feedback, and the cycle repeats until the output clears the bar, with a hard iteration limit to prevent runaway loops. It is how you get quality through refinement, for things like style-sensitive content, nuanced translation, or code that has to handle edge cases.
Durable Agent sits at the autonomous end of the spectrum. Rather than following predefined steps, it plans and executes its own, with the full reliability of durable execution behind it: every LLM call and tool execution persisted, every interaction recoverable. It is built for long-running tasks that might take minutes or days, for distributed systems, for multi-session work, and for “headless” agents triggered by other systems rather than by a human, exposed through APIs so external events and applications can invoke them. This is the pattern that turns an autonomous agent into something you can actually trust in production.
Having these seven patterns available from the start means teams are not reinventing orchestration logic for every new use case. They choose the right shape for the problem and let the runtime handle the execution.
What This Looks Like in Practice
Pull the pieces together and the value becomes concrete.
Imagine a customer-support system handling thousands of conversations at once. Each conversation is a lightweight agent. Idle conversations cost nothing because they scale to zero, yet resume instantly with full history when the customer replies. A complex ticket spawns an orchestrator that delegates to specialist agents for billing, technical diagnosis, and account history, then synthesizes a single answer. If a node restarts mid-ticket, no conversation is lost, because every step was checkpointed. Every interaction is traceable for quality and compliance, and each agent can touch only the systems it has been scoped to access.
Or imagine a back-office process that runs for days: an agent that monitors incoming documents, extracts and validates data, cross-references multiple databases, and escalates exceptions to a human. It is triggered not by a person but by external events. It survives outages, retries failed steps, and picks up exactly where it left off. It authenticates to each external system through managed secrets, never exposing a credential.
In both cases, the teams building these systems wrote agent logic. The durability, the scaling, the security, the observability, and the coordination were the runtime’s job.
The Developer Promise
All of this reduces to a single, simple promise.
You define your agent logic and your prompts. Everything else, scaling, communication, monitoring, recovery, security, just works.
The runtime handles durable execution so a crash never costs you a workflow. It handles auto-scaling so thousands of agents run on minimal hardware and idle agents cost nothing. It builds in security so trust is enforced rather than assumed. It delivers full observability so nothing your agents do is a mystery. It connects to your data so agents operate on real information. It gives developers a complete API surface so the repetitive scaffolding is already built. And it enables multi-agent orchestration so individual agents combine into systems far more capable than any one of them.
That is the difference between an agent that demos well and an agentic system that runs in production, reliably, securely, and at scale.
Closing
The hard part of agentic AI was never the agent. It was everything around the agent: the durability, the scale, the security, the visibility, the data access, the coordination. Those are the problems that quietly decide whether an agentic initiative makes it past the pilot or stalls out in a notebook, and they are exactly the problems that a framework reinventing infrastructure from scratch tends to make worse, not better.
Bud Agent Runtime exists so that those problems are already solved before you start. It builds on a proven distributed-systems foundation, applies it specifically to running agents, and hands your teams an execution layer that behaves like mature infrastructure from day one. While your teams focus on building intelligent agents, the runtime handles everything underneath, from durable execution and auto-scaling to security, observability, data connectivity, and multi-agent orchestration. The result is an infrastructure layer purpose-built to run production-grade agentic systems, reliably, securely, and at scale.
It is the foundation the Agents module in Bud AI Foundry is built on, and it is the reason the agents you build there are ready not just for a demo, but for the real world.




.png)